Come forse qualcuno di voi sa, per diversi anni ho lavorato nel mondo del marketing. L’idea di analizzare enormi quantità di dati sul comportamento online delle persone mi affascinava. Mi faceva sentire un pò Elliot in Mr. Robot, anche se con skills decisamente diverse (e forse con un pò più di sanità mentale).
Purtroppo però, nella realtà la precisione di questi dati lascia molto a desiderare. Spesso, se si misura la stessa cosa da piattaforme diverse si ottengono risultati diversi, anche se si utilizzano servizi della stessa azienda (celebre l’esempio di Google Ads vs Google Analytics. Tracci gli ordini dell’ecommerce con entrambi? Perfetto, non saprai a chi dei due credere). Senza poi menzionare i problemi di tracciamento dovuti ad aspetti esterni, come cookie banners, estensioni ad blockers, browsers privacy oriented, sistemi operativi privacy oriented, ecc.
Insomma, la gente pensa di avere a che fare con il Grande Fratello di Orwell e che siamo tutti controllati, ma in realtà manco so bene quanto guadagno con una campagna su Google.
E da qui mi è nata l’idea per questo nuovo progetto con AWS: invece che lamentarmi ho creato una situazione ideale in AWS con dati fittizi e mostro come il marketing potrebbe aiutare il mondo.
Eh si ragazzƏ, il marketing non è solo vendita di corsi sulle cripto ma può anche servire a qualcosa nel sociale.
Ecco l’idea: le persone dipendenti da sostanze, scommesse o altro potrebbero cercare online informazioni su come smettere, magari nei siti web dei SerD. Ma a volte questo non basta, serve l’aiuto di un assistente sociale che possa seguirti passo passo. E che cosa c’è di meglio che spiare ogni singola sessione di ogni singola persona e, nel caso in cui risulti interessato a risolvere la sua dipendenza, passare il contatto con numero di telefono e mail ad un assistente sociale che lo va a trovare a casa?
Privacy zero ovviamente, ma stavolta è per una buona causa.
Vantaggi:
- Dai dati di navigazione possiamo sapere chi degli utenti ha bisogno dei nostri servizi e abbiamo i dati per contattarlo
Dati:
- Fittizi, creati con il servizio Kinesis Data Generator, KDG
Il progetto, a grandi linee
Come già detto, tutto si basa su come gli utenti hanno navigato un sito web. Ma come è fatto questo sito? Ecco la sua struttura:

Ci sono quindi pagine più generali, con articoli di blog divisi per problematica affrontata; pagine con i nostri servizi e contatti per far conoscere cosa facciamo; pagine con delle guide su come affrontare le proprie dipendenze, sempre divise per problema; e infine delle pagine “recensione” dove gli utenti possono trovare storie di persone che hanno affrontato le stesse difficoltà e che grazie alla nostra associazione sono riuscite a uscire dalle dipendenze.
Vediamo poi uno schema di questo progetto fatto in AWS.
Ci sono quindi pagine più generali, con articoli di blog divisi per problematica affrontata; pagine con i nostri servizi e contatti per far conoscere cosa facciamo; pagine con delle guide su come affrontare le proprie dipendenze, sempre divise per problema; e infine delle pagine “recensione” dove gli utenti possono trovare storie di persone che hanno affrontato le stesse difficoltà e che grazie alla nostra associazione sono riuscite a uscire dalle dipendenze.
Vediamo poi uno schema di questo progetto fatto in AWS.
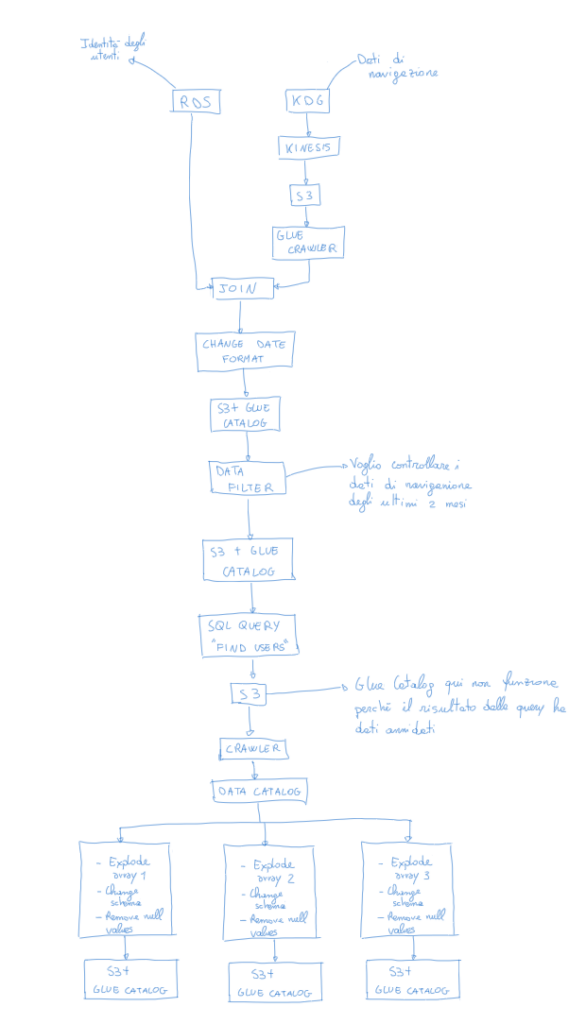
Si parte quindi con 2 sorgenti di dati: la prima contiene un registro di tutti gli utenti mentre la seconda contiene i loro dati di navigazione.
Tratto questi dati nella parte centrale, sistemando la loro tipologia e selezionando solo quelli relativi agli ultimi 2 mesi, per poi scegliere solo quelle persone che hanno avuto un comportamento specifico per cui possono essere interessati alla ricerca di una soluzione alle proprie dipendenze.
Devono aver visitato un pò tutto il nostro sito. Devono aver speso abbastanza tempo tra il nostro blog e le nostre guide di aiuto, così da selezionare solo le persone che effettivamente hanno dimostrato un coinvolgimento in queste tematiche. Devono poi aver letto chi siamo, quali sono i nostri servizi e le diverse recensioni disponibili, in modo da selezionare persone interessate anche alla nostra struttura o attività. Infine, devono aver scaricato il nostro PDF con la descrizione dettagliata dei servizi offerti.
Una volta selezionate queste persone, vado a salvare i loro User_Id all’interno di 3 diverse cartelle S3, in modo da poter inviare una mail all’assistente sociale di riferimento per quel problema.
Creazione dei dati
Users
I dati per l’identificazione degli utenti (User_Id, mail e phone) li ho inseriti manualmente in un database MySQL usando il servizio RDS e accedendo al database da una macchina virtuale EC2. Dovete solo ricordarvi di prendere nota dell’endpoint del database (il suo indirizzo), dell’user name e della password.
In questo modo, una volta collegatoci all’istanza EC2 ci basterà il comando:
Comando
mysql --host=database-exercise2.xxxxxx.eu-north-1.rds.amazonaws.com --user=yyyyyy--password=zzzzzz
Da qui potremmo collegarci e inserire i dati tramite il comando SQL che trovate in questo excel.
Quando si crea una nuova istanza EC2 è possibile specificare dei comandi Bash che l’istanza eseguirà al suo primo avvio, con privilegi da amministratore. In questo caso dobbiamo installare MariaDB in modo da avere un client MYSQL per connetterci al nostro server. Inseriamo quindi in “User data” le seguenti righe:
#!/bin/bash
yum install -y mariadb
Navigation data
I dati di navigazione sono formati da pochi e semplici elementi:
- User_id —> chi ha visitato quella pagina?
- Page —> quale pagina del sito ha visitato? Qui ho semplicemente preso lo schema del sito web che avete visto prima e in un excel ho creato tutti i possibili URL di questo sito.
- Date —> quando ha visitato la pagina?
- session_length —> quanto è durata la lettura di quella pagina?
Anche in questo caso avrei potuto semplicemente aggiungere una tabella al database creato prima e inserire i dati manualmente con un comando SQL, ma sia mai che mi perdo un’occasione per complicarmi la vita 😉.
Ho deciso di usare Kinesis Data Generator (KDG), un generatore di dati fittizi che AWS mette a disposizione in GitHub. Dato che è necessario creare un utente con il servizio Cognito per accedere a KDG, AWS ha messo a disposizione un template in Cloudformation per fare il lavoro sporco al posto nostro, disponibile nella pagina del link precedente.
Ma come si presenta il servizio KDG? Cosa possiamo fare con lui? Ecco qui uno screenshot:
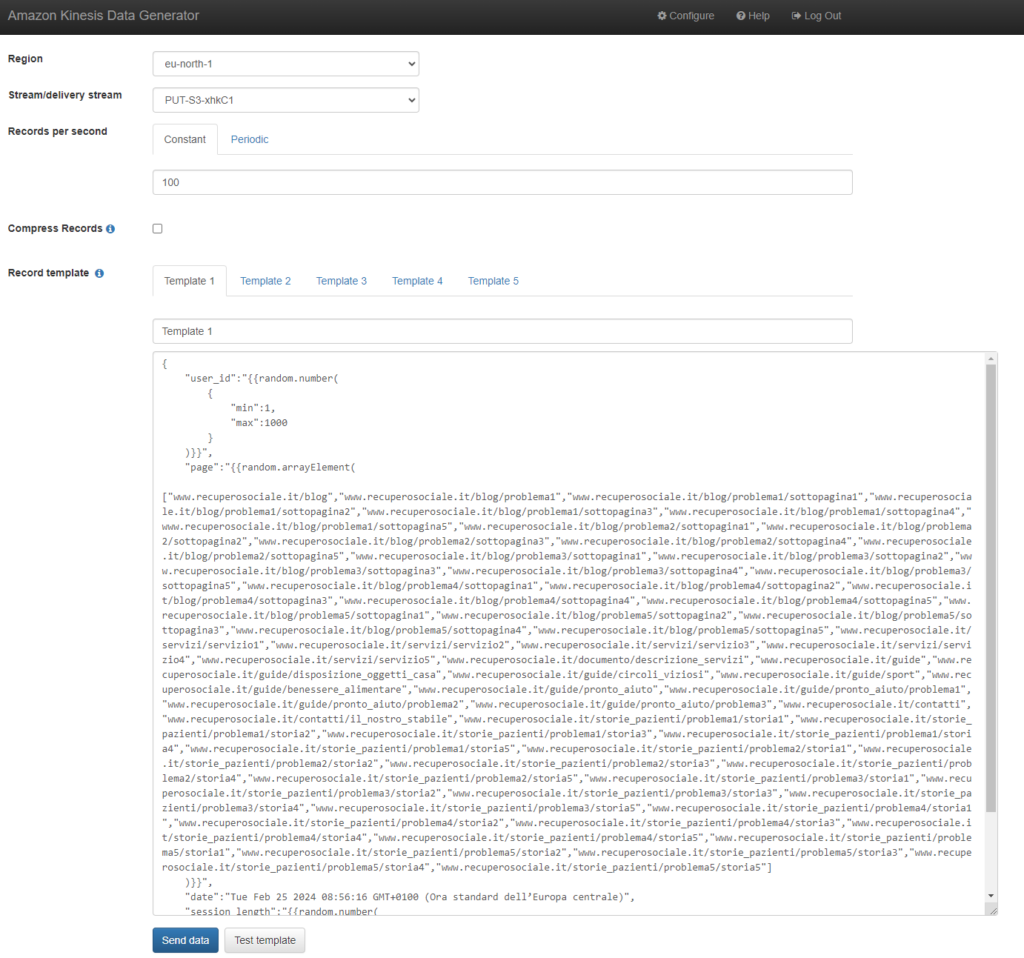
L’interfaccia è molto semplice. In alto possiamo scegliere la nostra region di riferimento e il delivery stream Kinesis in cui vogliamo direzionare i dati generati; scegliamo poi il numero di righe da creare per ogni secondo di utilizzo di questo servizio; infine sotto specifichiamo il template da utilizzare per la creazione di ognuna di queste righe.
Qui di seguito il template che ho usato:
Template
{
"user_id":"{{random.number(
{
"min":1,
"max":1000
}
)}}",
"page":"{{random.arrayElement(
["www.recuperosociale.it/blog","www.recuperosociale.it/blog/problema1","www.recuperosociale.it/blog/problema1/sottopagina1","www.recuperosociale.it/blog/problema1/sottopagina2","www.recuperosociale.it/blog/problema1/sottopagina3","www.recuperosociale.it/blog/problema1/sottopagina4","www.recuperosociale.it/blog/problema1/sottopagina5","www.recuperosociale.it/blog/problema2/sottopagina1","www.recuperosociale.it/blog/problema2/sottopagina2","www.recuperosociale.it/blog/problema2/sottopagina3","www.recuperosociale.it/blog/problema2/sottopagina4","www.recuperosociale.it/blog/problema2/sottopagina5","www.recuperosociale.it/blog/problema3/sottopagina1","www.recuperosociale.it/blog/problema3/sottopagina2","www.recuperosociale.it/blog/problema3/sottopagina3","www.recuperosociale.it/blog/problema3/sottopagina4","www.recuperosociale.it/blog/problema3/sottopagina5","www.recuperosociale.it/blog/problema4/sottopagina1","www.recuperosociale.it/blog/problema4/sottopagina2","www.recuperosociale.it/blog/problema4/sottopagina3","www.recuperosociale.it/blog/problema4/sottopagina4","www.recuperosociale.it/blog/problema4/sottopagina5","www.recuperosociale.it/blog/problema5/sottopagina1","www.recuperosociale.it/blog/problema5/sottopagina2","www.recuperosociale.it/blog/problema5/sottopagina3","www.recuperosociale.it/blog/problema5/sottopagina4","www.recuperosociale.it/blog/problema5/sottopagina5","www.recuperosociale.it/servizi/servizio1","www.recuperosociale.it/servizi/servizio2","www.recuperosociale.it/servizi/servizio3","www.recuperosociale.it/servizi/servizio4","www.recuperosociale.it/servizi/servizio5","www.recuperosociale.it/documento/descrizione_servizi","www.recuperosociale.it/guide","www.recuperosociale.it/guide/disposizione_oggetti_casa","www.recuperosociale.it/guide/circoli_viziosi","www.recuperosociale.it/guide/sport","www.recuperosociale.it/guide/benessere_alimentare","www.recuperosociale.it/guide/pronto_aiuto","www.recuperosociale.it/guide/pronto_aiuto/problema1","www.recuperosociale.it/guide/pronto_aiuto/problema2","www.recuperosociale.it/guide/pronto_aiuto/problema3","www.recuperosociale.it/contatti","www.recuperosociale.it/contatti/il_nostro_stabile","www.recuperosociale.it/storie_pazienti/problema1/storia1","www.recuperosociale.it/storie_pazienti/problema1/storia2","www.recuperosociale.it/storie_pazienti/problema1/storia3","www.recuperosociale.it/storie_pazienti/problema1/storia4","www.recuperosociale.it/storie_pazienti/problema1/storia5","www.recuperosociale.it/storie_pazienti/problema2/storia1","www.recuperosociale.it/storie_pazienti/problema2/storia2","www.recuperosociale.it/storie_pazienti/problema2/storia3","www.recuperosociale.it/storie_pazienti/problema2/storia4","www.recuperosociale.it/storie_pazienti/problema2/storia5","www.recuperosociale.it/storie_pazienti/problema3/storia1","www.recuperosociale.it/storie_pazienti/problema3/storia2","www.recuperosociale.it/storie_pazienti/problema3/storia3","www.recuperosociale.it/storie_pazienti/problema3/storia4","www.recuperosociale.it/storie_pazienti/problema3/storia5","www.recuperosociale.it/storie_pazienti/problema4/storia1","www.recuperosociale.it/storie_pazienti/problema4/storia2","www.recuperosociale.it/storie_pazienti/problema4/storia3","www.recuperosociale.it/storie_pazienti/problema4/storia4","www.recuperosociale.it/storie_pazienti/problema4/storia5","www.recuperosociale.it/storie_pazienti/problema5/storia1","www.recuperosociale.it/storie_pazienti/problema5/storia2","www.recuperosociale.it/storie_pazienti/problema5/storia3","www.recuperosociale.it/storie_pazienti/problema5/storia4","www.recuperosociale.it/storie_pazienti/problema5/storia5"]
)}}",
"date":"Tue Feb 25 2024 08:56:16 GMT+0100 (Ora standard dell’Europa centrale)",
"session_length":"{{random.number(
{
"min":1,
"max":2500
}
)}}"
}
In realtà ho passato abbastanza tempo su questo punto. Non è chiarissimo quale sintassi si possa utilizzare in questi template e alcune pagine linkate da AWS non sono più esistenti. Sopratutto per la creazione di date che mi permettessero di testare il filtro degli ultimi 2 mesi, alla fine per semplicità ho scritto a mano una data specifica che è stata ripetuta per migliaia di righe.
I dati generati da KDG vengono passati ad un Firehose di Kinesis che li trasporta e salva all’interno di una cartella S3 e vengono poi letti da un Glue Crawler che li salva in una tabella Glue Data Catalog. In questo modo sono belli freschi per poi essere utilizzati nelle nostre ETL.
ETL con Glue ETL Jobs
Veniamo ora alla parte centrale di questo progetto. Per sminuzzare e pulire e dati ho deciso di utilizzare i Job disponibili all’interno del servizio Glue. Ci è in questo modo possibile creare dei piccoli schemi e di azionarli uno alla volta in base alla fase in cui siamo con i nostri dati.
Perchè piccoli schemi e non un unico grande schema come nell’immagine sopra? Eh perchè per qualche motivo se mettevo in fila due modifiche fatte con SQL, ottenevo come risultato una tabella vuota. Appena ho iniziato a spezzettare il flusso, è tornato a funzionare. Ho chiesto maggiori informazioni ai guru di reddit ma non siamo riusciti a venirne a capo 🙃.
Vediamo i piccoli schemi costruiti:
ETL 1
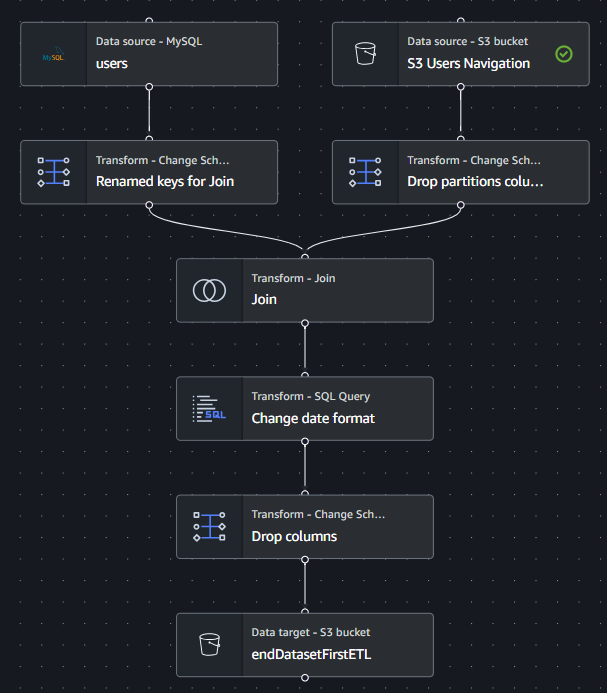
In questa prima ETL andiamo a unire i dati di navigazione degli utenti con quelli che sono i dati degli utenti stessi. In questo modo avremo un singolo dataset con tutto ciò che ci serve. Cogliamo l’occasione anche per sistemare le tipologie delle colonne perchè da KDG ci arrivano tutte in formato stringa. La questione è particolarmente spinosa per le date. Infatti le dobbiamo pulire con la seguente riga in SQL:
Codice
select DATE_FORMAT(TO_DATE(SUBSTRING(date, 5, 11), 'MMM dd yyyy'), 'yyyy-MM-dd') AS formatted_date, * from myDataSource
In questo modo avremo una bellissima data in formato “yyyy-MM-dd”. Eliminiamo qualche colonna risultante dal Join che non ci è utile e il risultato è questo:

Dato che vogliamo far collegare il servizio Glue direttamente al database RDS, dobbiamo ricordarci di settare una VPC e di includere i vari servizi all’interno dello stesso security group. Trovate maggiori informazioni in questa pagina della documentazione di AWS. https://docs.aws.amazon.com/glue/latest/dg/setup-vpc-for-glue-access.html
ETL 2
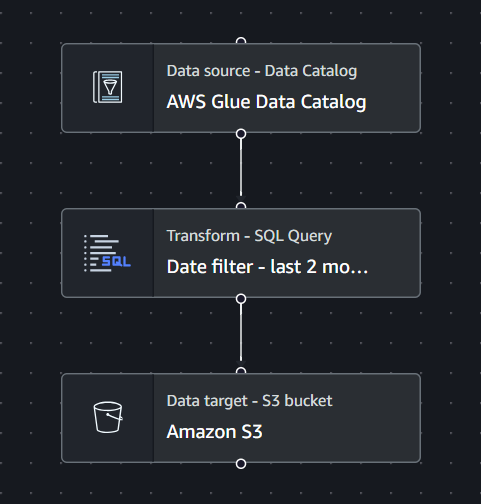
Con la seconda ETL vado a prendere come sorgente il risultato dell’ETL precedente e seleziono solo i dati di navigazione relativi ai 2 mesi precedenti. Non voglio infatti trattare anche i dati di gente che ha visitato il sito un anno fa. Dato che devo passare il contatto ad un assistente sociale, voglio che la lead sia ancora calda (da notare lo slang marketing).
Codice
select * from myDataSource
WHERE formatted_date BETWEEN date_trunc('month', current_date) + interval '-2' month AND date_trunc('month', current_date) + interval '0' month - interval '1' day
Salvo tutto all’interno di una cartella S3.
ETL 3
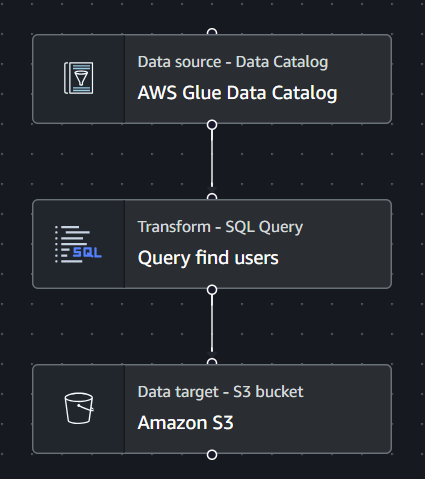
Qui c’è la query SQL succosa, quella da mostrare a Natale ai parenti per farti sembrare un Hacker che potrebbe attaccare il Pentagono.
In input ci prendiamo il risultato dell’ETL precedente e poi andiamo a selezionarci gli utenti che sono interessati a noi e ai nostri servizi.
Qui la query completa:
Codice
with first_filter as (
SELECT DISTINCT *
FROM myDataSource
WHERE user_id IN (
SELECT user_id FROM myDataSource WHERE page = 'www.recuperosociale.it/contatti/il_nostro_stabile' AND session_length >= 60
) AND user_id IN (
SELECT user_id FROM myDataSource WHERE page = 'www.recuperosociale.it/documento/descrizione_servizi'
)
),
second_filter_prob1 as(
SELECT DISTINCT user_id
FROM first_filter
WHERE user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema1/sottopagina1' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema1/sottopagina2' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema1/sottopagina3' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema1/sottopagina4' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema1/sottopagina5' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/guide/pronto_aiuto/problema1' AND session_length >= 1500
) AND user_id IN (
SELECT user_id
FROM (
SELECT user_id,
SUM(CASE WHEN page IN ('www.recuperosociale.it/storie_pazienti/problema1/storia1',
'www.recuperosociale.it/storie_pazienti/problema1/storia2',
'www.recuperosociale.it/storie_pazienti/problema1/storia3',
'www.recuperosociale.it/storie_pazienti/problema1/storia4',
'www.recuperosociale.it/storie_pazienti/problema1/storia5')
AND session_length >= 900 THEN 1 ELSE 0 END) AS visits
FROM myDataSource
GROUP BY user_id
)
WHERE visits >= 3
)
),
second_filter_prob2 as(
SELECT DISTINCT user_id
FROM first_filter
WHERE user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema2/sottopagina1' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema2/sottopagina2' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema2/sottopagina3' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema2/sottopagina4' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema2/sottopagina5' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/guide/pronto_aiuto/problema2' AND session_length >= 1500
) AND user_id IN (
SELECT user_id
FROM (
SELECT user_id,
SUM(CASE WHEN page IN ('www.recuperosociale.it/storie_pazienti/problema2/storia1',
'www.recuperosociale.it/storie_pazienti/problema2/storia2',
'www.recuperosociale.it/storie_pazienti/problema2/storia3',
'www.recuperosociale.it/storie_pazienti/problema2/storia4',
'www.recuperosociale.it/storie_pazienti/problema2/storia5')
AND session_length >= 900 THEN 1 ELSE 0 END) AS visits
FROM myDataSource
GROUP BY user_id
)
WHERE visits >= 3
)
),
second_filter_prob3 as(
SELECT DISTINCT user_id
FROM first_filter
WHERE user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema3/sottopagina1' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema3/sottopagina2' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema3/sottopagina3' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema3/sottopagina4' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/blog/problema3/sottopagina5' AND session_length >= 600
) AND user_id IN (
SELECT user_id FROM first_filter WHERE page = 'www.recuperosociale.it/guide/pronto_aiuto/problema3' AND session_length >= 1500
) AND user_id IN (
SELECT user_id
FROM (
SELECT user_id,
SUM(CASE WHEN page IN ('www.recuperosociale.it/storie_pazienti/problema3/storia1',
'www.recuperosociale.it/storie_pazienti/problema3/storia2',
'www.recuperosociale.it/storie_pazienti/problema3/storia3',
'www.recuperosociale.it/storie_pazienti/problema3/storia4',
'www.recuperosociale.it/storie_pazienti/problema3/storia5')
AND session_length >= 900 THEN 1 ELSE 0 END) AS visits
FROM myDataSource
GROUP BY user_id
)
WHERE visits >= 3
)
)
SELECT
(SELECT ARRAY_AGG(user_id) FROM second_filter_prob1) AS probFirst,
(SELECT ARRAY_AGG(user_id) FROM second_filter_prob2) AS probSecond,
(SELECT ARRAY_AGG(user_id) FROM second_filter_prob3) AS probThird;
Nella subquery chiamata “first_filter” andiamo a selezionare le persone che hanno visitato l’URL www.recuperosociale.it/contatti/il_nostro_stabile per minimo un minuto. Almeno si sono letti le indicazioni stradali per arrivare a noi.
Vogliamo poi solo le persone che hanno scaricato il nostro PDF descrittivo visitando l’URL www.recuperosociale.it/documento/descrizione_servizi.
Le altre 3 subquery sono uguali come logica ma si rifanno a 3 problemi di dipendenza diversi. In questo modo posso inviare all’assistente sociale solo leads di sua competenza.
In ognuna di queste,andiamo a selezionare solo le persone che hanno letto i diversi articoli di blog su uno specifico problema e che hanno passato abbastanza tempo nella nostra guida di pronto aiuto su quel problema. Infine, scegliamo solo le persone che hanno letto almeno 3 delle nostre 5 recensioni che abbiamo su quello specifico problema.
Alla fine di questo processo avremo il nostro gruppo di persone che probabilmente hanno un problema di dipendenza (o una persona a loro vicino), sono interessati ai nostri servizi e hanno anche letto le diverse recensioni.
Dato che i dati finali sono in forma annidata (un array di User_id in ogni cella della tabella finale), significa che dobbiamo prima salvare i dati all’interno di una cartella S3 ma che poi li dobbiamo andare a leggere con un Crawler in modo da averli pronti per la prossima ETL.

ETL 4
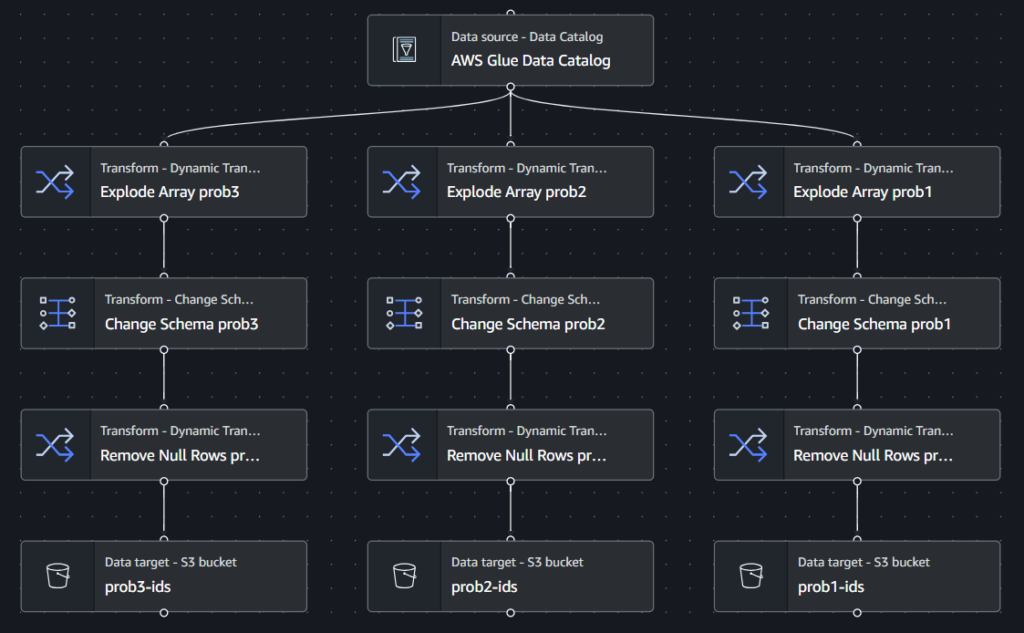
In questo caso dobbiamo solamente dividere gli User_id trovati in precedenza in diversi flussi in base al problema a cui fanno riferimento. Andiamo a “esplodere” gli array, in modo da avere una semplice colonna con tutti gli User_id, rimuoviamo colonne non utili, valori null e il gioco è fatto. Alla fine avremo solamente i dati che ci servono e in formato facilmente leggibile.
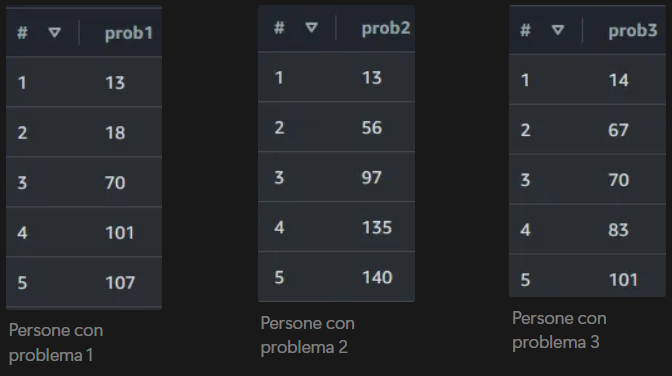
Vediamo subito come ci siano persone appartenenti a più categorie, come gli utenti 13 e 101. Potrebbe essere che queste persone sia meglio gestirle in altro modo, ma al momento verranno segnalate a più assistenti sociali.
Ora dobbiamo ricordarci si fare un Join tra queste ultime tabelle e la tabella nel nostro RDS dove abbiamo tutti i dati sugli utenti. Fatto questo possiamo salvare questi diversi file in diverse cartelle S3. Il problema però è che questi file sono di fatto CSV, ma senza l’estensione “.csv” alla fine.
Sarebbe troppo facile.
Ho quindi bisogno di una funzione Lambda (ho anche provato a fare questa cosa in Glue Studio usando un Job in versione codice ma era più complicato del previsto. Ci ho dedicato un’ora e poi ho risolto in 10 minuti con una Lambda).
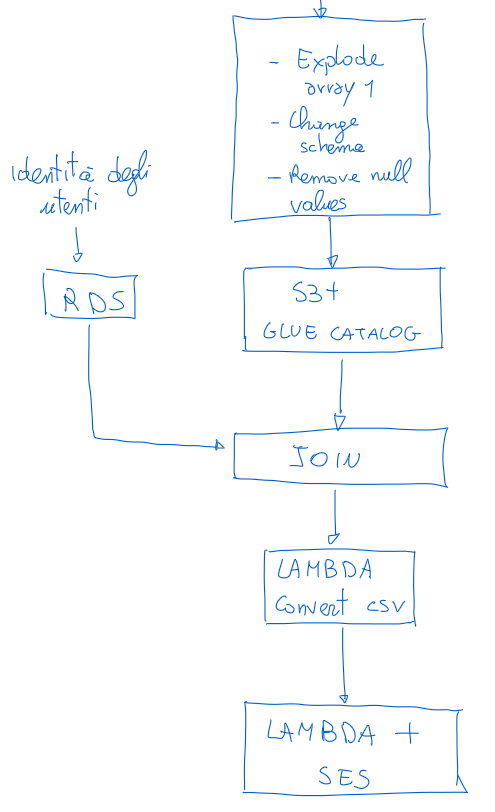
Rinominare il file e invio della mail
Questa funzione Lambda semplicemente prende il file caricato in recupero-sociale/prob1-users/ e lo ricarica nella cartella recupero-sociale/prob1-users-csv/ aggiungendoci l’estensione “.csv”.
Codice della funzione Lambda
import boto3
import urllib.parse
s3 = boto3.client('s3')
def lambda_handler(event, context):
# Get the source bucket and object key from the event
source_bucket = event['Records'][0]['s3']['bucket']['name']
source_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
print("source_bucket: {source_bucket}")
print("source_key: {source_key}")
# Define the destination folder and filename
destination_folder = 'recupero-sociale/prob1-users-csv'
destination_filename = 'output_file.csv'
# Define the destination key
destination_key = f"{destination_folder}/{destination_filename}"
try:
# Copy the object to the new destination
s3.copy_object(
Bucket=source_bucket,
CopySource={'Bucket': source_bucket, 'Key': source_key},
Key=destination_key
)
print(f"File copied from {source_key} to {destination_key}")
return {
'statusCode': 200,
'body': 'File copied successfully'
}
except Exception as e:
print(f"Error copying file: {e}")
return {
'statusCode': 500,
'body': f"Error copying file: {e}"
}
Infine, il fatto che nella nuova cartella venga depositato un file triggera la nostra ultima Lambda, che invia una mail con questo file in allegato.
Codice altra funzione Lambda
import os.path
import boto3
import email
from botocore.exceptions import ClientError
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.application import MIMEApplication
s3 = boto3.client("s3")
def lambda_handler(event, context):
# Replace sender@example.com with your "From" address.
# This address must be verified with Amazon SES.
SENDER = "test@test.com"
# Replace recipient@example.com with a "To" address. If your account
# is still in the sandbox, this address must be verified.
RECIPIENT = "test@test.com"
# Specify a configuration set. If you do not want to use a configuration
# set, comment the following variable, and the
# ConfigurationSetName=CONFIGURATION_SET argument below.
# CONFIGURATION_SET = "ConfigSet"
AWS_REGION = "eu-north-1"
SUBJECT = "Dati Recupero Sociale"
# This is the start of the process to pull the files we need from the S3 bucket into the email.
# Get the records for the triggered event
FILEOBJ = event["Records"][0]
# Extract the bucket name from the records for the triggered event
BUCKET_NAME = str(FILEOBJ['s3']['bucket']['name'])
# Extract the object key (basicaly the file name/path - note that in S3 there are
# no folders, the path is part of the name) from the records for the triggered event
KEY = str(FILEOBJ['s3']['object']['key'])
# extract just the last portion of the file name from the file. This is what the file
# would have been called prior to being uploaded to the S3 bucket
FILE_NAME = os.path.basename(KEY)
# Using the file name, create a new file location for the lambda. This has to
# be in the tmp dir because that's the only place lambdas let you store up to
# 500mb of stuff, hence the '/tmp/'+ prefix
TMP_FILE_NAME = '/tmp/' +FILE_NAME
# Download the file/s from the event (extracted above) to the tmp location
s3.download_file(BUCKET_NAME, KEY, TMP_FILE_NAME)
# Make explicit that the attachment will have the tmp file path/name. You could just
# use the TMP_FILE_NAME in the statments below if you'd like.
ATTACHMENT = TMP_FILE_NAME
# The email body for recipients with non-HTML email clients.
BODY_TEXT = "Altre persone hanno bisogno di te!,\r\nIn allegato trovo il CSV con i numeri di telefono ed email."
# The HTML body of the email.
BODY_HTML = """\
<html>
<head></head>
<body>
<h1>Altre persone hanno bisogno di te!</h1>
<p>In allegato trovi il CSV con i numeri di telefono ed email.</p>
</body>
</html>
"""
# The character encoding for the email.
CHARSET = "utf-8"
# Create a new SES resource and specify a region.
client = boto3.client('ses',region_name=AWS_REGION)
# Create a multipart/mixed parent container.
msg = MIMEMultipart('mixed')
# Add subject, from and to lines.
msg['Subject'] = SUBJECT
msg['From'] = SENDER
msg['To'] = RECIPIENT
# Create a multipart/alternative child container.
msg_body = MIMEMultipart('alternative')
# Encode the text and HTML content and set the character encoding. This step is
# necessary if you're sending a message with characters outside the ASCII range.
textpart = MIMEText(BODY_TEXT.encode(CHARSET), 'plain', CHARSET)
htmlpart = MIMEText(BODY_HTML.encode(CHARSET), 'html', CHARSET)
# Add the text and HTML parts to the child container.
msg_body.attach(textpart)
msg_body.attach(htmlpart)
# Define the attachment part and encode it using MIMEApplication.
att = MIMEApplication(open(ATTACHMENT, 'rb').read())
# Add a header to tell the email client to treat this part as an attachment,
# and to give the attachment a name.
att.add_header('Content-Disposition','attachment',filename=os.path.basename(ATTACHMENT))
# Attach the multipart/alternative child container to the multipart/mixed
# parent container.
msg.attach(msg_body)
# Add the attachment to the parent container.
msg.attach(att)
print(msg)
try:
#Provide the contents of the email.
response = client.send_raw_email(
Source=SENDER,
Destinations=[
RECIPIENT
],
RawMessage={
'Data':msg.as_string(),
},
# ConfigurationSetName=CONFIGURATION_SET
)
# Display an error if something goes wrong.
except ClientError as e:
print(e.response['Error']['Message'])
else:
print("Email sent! Message ID:"),
print(response['MessageId'])
Ecco qui di seguito il risultato:
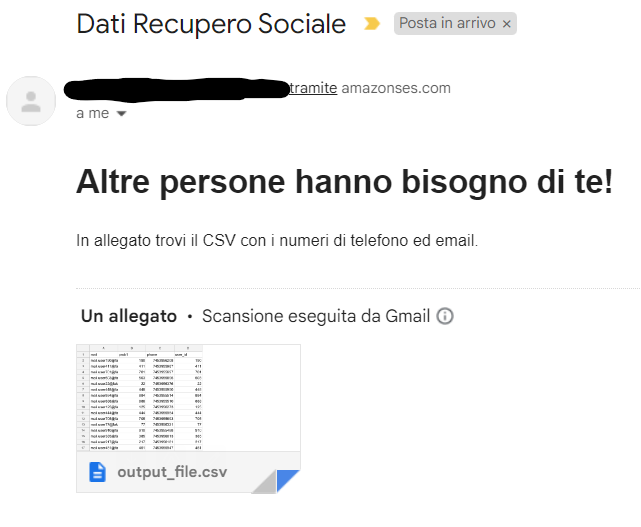
Il nostro assistente sociale si vede arrivare direttamente via email il csv con tutto ciò che gli serve per contattare le persone che, in base a come hanno navigato il nostro sito, potrebbero avere un problema di dipendenza da risolvere e sono interessate alla nostra attività.
E con questo è tutto 👍 Palesemente lo stesso procedimento può essere usato da un’azienda per trovare nuovi clienti, ma come detto all’inizio, la precisione dei dati marketing nel mondo reale rende molto difficile un’analisi di questo tipo.
Grazie AWS e KDG per lasciarci sognare.