Quando si vuole gestire i flussi di dati di un’azienda si devono fare molte cose: bisogna occuparsi dei dati in entrata, pulirli, catalogarli, elaborarli, magari incrociarli con dati provenienti da altre fonti, prepararli per lo strumento di visualizzazione e finalmente creare i grafici che tanto piacciono ai piani alti.
La struttura per l’elaborazione deve essere poi sempre attiva, deve rimanere in attesa di un momento specifico della giornata o che si verifichi qualche evento che segnali “hei qui ci sono nuovi dati da elaborare”. Sarebbe poi una bella sfortuna se chi deve gestire questi dati debba fare sempre le stesse operazioni manualmente.
Proprio per questo motivo non può mai mancare uno strumento che possa gestire altri strumenti, un direttore d’orchestra che fa funzionare tutto con il giusto tempismo.

Così ho deciso di approfondire il funzionamento di Step Function in AWS. Questo servizio permette di attivare Lambda, strumenti di Glue o molto altro al verificarsi di eventi specifici.
Vantaggi:
- Automatizzare intere pipeline nella gestione di dati
Dati:
- generati con KDG
L’esempio: dati di navigazione e recensioni
Immaginiamo di avere un’azienda con a disposizione strumenti per la raccolta dei dati di navigazione del proprio sito web e delle recensioni che utenti lasciano sui diversi prodotti (GA4, giusto per fare un nome).
Purtroppo però questi strumenti possono avere difetti e possono inviare ad AWS batch di dati non sempre uguali ai precedenti. Ecco perché dobbiamo controllare la qualità dei dati in entrata e, in caso non siano conformi, prendere degli accorgimenti.
Nell’esempio che segue, con KDG (Kinesis Data Generator) genero i dati che mi servono ma inserisco al loro interno anche qualche errore. Nel caso dei dati di navigazione ipotizzo che alcuni batch possano avere delle colonne che nelle iterazioni precedenti non erano presenti, mentre nel caso delle recensioni ipotizzo degli errori negli URL.
Appena questi dati vengono salvati in una cartella S3, viene inviato un segnale a Step Function tramite Event Bridge. La Step Function attiva quindi diverse Lambda che 1) sistemano la formattazione delle date (maledette date), 2) confrontano i dati con quelli già presenti in AWS o se i dati in entrata presentano degli errori, 3) spostano i dati nella Clean Zone e attivano il Glue Crawler che li caricherà nella giusta tabella.
Tutto questo per fare in modo che a PowerBI arrivino dati aggiornati e con i giusti formati. Rendiamo la vita facile ai data analyst.
Generazione dei dati con KDG
Come anche in altri articoli, ho utilizzato KDG per creare i dati che mi servivano. Sono fittizi e in questo modo posso testare le funzioni che andrò a creare.
KDG dati di navigazione
Qui il template per i dati di navigazione. Manualmente aggiungevo una colonna per simulare una differenza rispetto ai dati inviati precedentemente.
{
"user_id":"{{random.number(
{
"min":1,
"max":1000
}
)}}",
"page":"{{random.arrayElement(
["page1","page2","page3","page4","page5","page6","page7","page8","page9","page10","page11","page12","page13","page14","page15","page16","page17","page18","page19","page20","page21","page22","page23","page24","page25","page26","page27","page28","page29","page30","page31","page32","page33","page34","page35","page36","page37","page38","page39","page40","page41","page42","page43","page44","page45","page46","page47","page48","page49","page50","page51","page52","page53","page54","page55","page56","page57","page58","page59","page60","page61","page62","page63","page64","page65","page66","page67","page68","page69","page70","page71","page72","page73","page74","page75","page76","page77","page78","page79","page80","page81","page82","page83","page84","page85","page86","page87","page88","page89","page90","page91","page92","page93","page94","page95","page96","page97","page98","page99","page100"]
)}}",
"date_websitestats":"{{date.past}}"
}
KDG recensioni
Qui il template per le recensioni. Nell’url possono esserci errori di vario tipo
{
"user_id":"{{random.number(
{
"min":1,
"max":1000
}
)}}",
"url":"{{random.arrayElement(
["www.myveryownreview.com","wwww.myveryownreview.com","www..myveryownreview.com","www.myveryownreview.como"]
)}}",
"reviewText":"{{random.arrayElement(
["first review","second review","third review","fourth review"]
)}}",
"reviews_date":"{{date.past}}"
}
Tramite Kinesis Firehose, questi dati vengono salvati in specifiche cartelle S3, in modo da creare una landing zone. Qui bisogna ricordarsi che ogni cosa che arriva da KDG viene inizialmente salvata come stringa e che quindi, dopo il primo scan del crawler, è meglio cambiare la tipologia delle colonne nello schema della tabella in Glue Catalog. Purtroppo però questo non basta per le date. Bisogna andare a modificare proprio i valori all’interno delle celle. Ecco perchè il prossimo passaggio è una Lambda che fa proprio questo.
Prima Lambda
I valori per le date da KDG escono in questo modo:
“Tue Apr 30 2024 03:09:22 GMT+0200 (Ora legale dell’Europa centrale)”
ma per renderli riconoscibili anche a Power Bi devo modificarli. Questo viene fatto tramite una Lambda specifica. Va a leggersi i file Json in entrata, li trasforma in dataframe e va a modificare ogni singola riga per ottenere la data nel formato che desideriamo. Il dataframe viene poi salvato in formato csv in un’altra cartella S3, sempre nella landing zone.
Lambda modifica date dati di navigazione
import json
import boto3
import pandas as pd
from datetime import datetime
from io import StringIO
def convert_date_string(date_str):
#convert date format
date_obj = datetime.strptime(date_str, "%a %b %d %Y %H:%M:%S GMT%z")
formatted_date = date_obj.strftime("%Y-%m-%d %H:%M:%S")
return formatted_date
def lambda_handler(event, context):
#initialize S3 client and specify the folder we want to read
s3 = boto3.client('s3')
bucket_name = 'landing-zone-step-function'
folder_name = 'website-stats/kinesis/'
#list objects in the folder
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=folder_name)
#read json data in that folder and put everything in a list from which we will create a dataframe
json_data = []
for obj in response['Contents']:
if obj['Key'].endswith('.json'):
file_obj = s3.get_object(Bucket=bucket_name, Key=obj['Key'])
file_content = file_obj['Body'].read().decode('utf-8')
# Split file content by newline characters
records = file_content.strip().split('\n')
for record in records:
json_data.append(json.loads(record))
#create DataFrame from JSON data
df = pd.DataFrame(json_data)
#change format date values
df['date_websitestats'] = df['date_websitestats'].apply(lambda x: x[:33])
df['date_websitestats'] = df['date_websitestats'].apply(lambda x: convert_date_string(x))
#convert DataFrame to CSV
csv_buffer = StringIO()
df.to_csv(csv_buffer, index=False)
#connect to S3
s3_resource = boto3.resource('s3')
#specify the bucket and file name where we want to past our csv
destination_bucket_name = 'landing-zone-step-function'
destination_folder_name = 'website-stats/past-data'
#generate current date and time as the file name
current_datetime = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
file_name = f'{current_datetime}.csv'
#upload CSV file to S3
s3_resource.Object(destination_bucket_name, f'{destination_folder_name}/{file_name}').put(Body=csv_buffer.getvalue())
#delete all files in old folder
if 'Contents' in response:
for obj in response['Contents']:
if obj['Key'] == folder_name: #this is because I don't want to delete the main folder, but just files in it
pass
else:
source_key = obj['Key']
s3.delete_object(Bucket=bucket_name, Key=source_key)
return {
'statusCode': 200,
'body': json.dumps('Success!')
}
Lambda modifica date recensioni
import json
import boto3
import pandas as pd
from datetime import datetime
from io import StringIO
def convert_date_string(date_str):
#convert date format
date_obj = datetime.strptime(date_str, "%a %b %d %Y %H:%M:%S GMT%z")
formatted_date = date_obj.strftime("%Y-%m-%d %H:%M:%S")
return formatted_date
def lambda_handler(event, context):
#initialize S3 client and specify the folder we want to read
s3 = boto3.client('s3')
bucket_name = 'landing-zone-step-function'
folder_name = 'reviews/kinesis/'
#list objects in the folder
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=folder_name)
#read json data in that folder and put everything in a list from which we will create a dataframe
json_data = []
for obj in response['Contents']:
if obj['Key'].endswith('.json'):
file_obj = s3.get_object(Bucket=bucket_name, Key=obj['Key'])
file_content = file_obj['Body'].read().decode('utf-8')
# Split file content by newline characters
records = file_content.strip().split('\n')
for record in records:
json_data.append(json.loads(record))
#create DataFrame from JSON data
df = pd.DataFrame(json_data)
#change format date values
df['reviews_date'] = df['reviews_date'].apply(lambda x: x[:33])
df['reviews_date'] = df['reviews_date'].apply(lambda x: convert_date_string(x))
#convert DataFrame to CSV
csv_buffer = StringIO()
df.to_csv(csv_buffer, index=False)
#connect to S3
s3_resource = boto3.resource('s3')
#specify the bucket and file name where we want to past our csv
destination_bucket_name = 'landing-zone-step-function'
destination_folder_name = 'reviews/past-data'
#generate current date and time as the file name
current_datetime = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
file_name = f'reviews-{current_datetime}.csv'
#upload CSV file to S3
s3_resource.Object(destination_bucket_name, f'{destination_folder_name}/{file_name}').put(Body=csv_buffer.getvalue())
#delete all files in old folder
if 'Contents' in response:
for obj in response['Contents']:
if obj['Key'] == folder_name: #this is because I don't want to delete the main folder, but just files in it
pass
else:
source_key = obj['Key']
s3.delete_object(Bucket=bucket_name, Key=source_key)
return {
'statusCode': 200,
'body': json.dumps('Success!')
}
Seconda Lambda
La seconda Lambda controlla invece che i nuovi dati siano “buoni” o se abbiano qualche problema. Come detto in precedenza, gli errori che ho ipotizzato per i dati di navigazione e per il sito web sono diversi, quindi abbiamo bisogno di 2 funzioni distinte.
Lambda controllo dati di navigazione
In questo caso vado a controllare se ci sono nuove colonne nei dati che voglio importare. La prima versione dei dati che carico tramite KDG ha le colonne:
- user_id
- page
- date_websitestats
Nel caso in cui i nuovi dati abbiano delle nuove colonne, verrà inviata una notifica via mail tramite il servizio SNS. In questo modo un nostro sviluppatore potrà prendersi in carico il task di capire cosa stia succedendo e se è il caso di chiamare incazzati i fornitori di quei dati.
Qui il codice della Lambda:
import json
import boto3
import pandas as pd
def lambda_handler(event, context):
#initialize S3 client
s3 = boto3.client('s3')
# Specify bucket name and folder
bucket_name = 'landing-zone-step-function'
folder_name = 'website-stats/past-data/'
#list objects in the folder
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=folder_name)
#there must be only one csv in the folder, so as soon as we recognize a csv file, we create a dataframe from it
for obj in response['Contents']:
if obj['Key'].endswith('.csv'):
file_obj = s3.get_object(Bucket=bucket_name, Key=obj['Key'])
new_df = pd.read_csv(file_obj['Body'])
#get the columns of the new data that we want to import
new_columns = new_df.columns.values.tolist()
#get the columns of the dataset saved in glue catalog
glue_client = boto3.client('glue')
#specify the database and table name
database_name = 'marketing-agency'
table_name = 'raw-website-statswebsite_stats'
#get table details from Glue catalog
response = glue_client.get_table(DatabaseName=database_name, Name=table_name)
#get the S3 path where the data is stored
s3_path = response['Table']['StorageDescriptor']['Location']
#extract column names
old_columns = [col['Name'] for col in response['Table']['StorageDescriptor']['Columns']]
for column in new_columns:
if column in old_columns:
pass
else:
return "ErrorNewColumns"
return "NoNewColumns"
Lambda controllo recensioni
La seconda funzione è relativa al controllo dei link delle recensioni. Nei dati inviati da KDG possono esserci delle recensioni con URL non funzionanti, come wwww.sito.com o www..sito.com.
Questa nostra funzione si passerà tutti record dei dati in entrata e controllerà quanti di essi presentano errori. In caso ce ne siano, invia una notifica via email ad uno sviluppatore che potrà andare a controllare quale sia l’errore e se è il caso di fare qualcosa di conseguenza. La funzione Lambda non corregge autonomamente gli errori e non scarta le recensioni se l’URL è sbagliato. semplicemente i dati vengono caricati comunque in Glue Catalog ma qualcuno nell’azienda saprà che c’è un problema da risolvere.
Qui il codice della funzione:
import json
import boto3
import pandas as pd
import re
from io import StringIO
from datetime import datetime
def lambda_handler(event, context):
#initialize S3 client
s3 = boto3.client('s3')
#specify bucket name and folder
bucket_name = 'landing-zone-step-function'
folder_name = 'reviews/past-data/'
#list objects in the folder
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=folder_name)
#there must be only one csv in the folder, so as soon as we recognize a csv file, we create a dataframe from it
for obj in response['Contents']:
if obj['Key'].endswith('.csv'):
file_obj = s3.get_object(Bucket=bucket_name, Key=obj['Key'])
reviews_df = pd.read_csv(file_obj['Body'])
n_invalid_urls = 0
#define regex pattern for valid URLs
url_pattern = re.compile(r'^www\.[a-zA-Z0-9-]+\.[a-zA-Z]{2,}$')
#check each URL in the 'url' column using regex
for url in reviews_df['url']:
if not url_pattern.match(url):
n_invalid_urls += 1
if n_invalid_urls > 0:
return "invalidUrls"
else:
return "onlyValidUrls"
Terza Lambda
La terza Lambda serve solo per spostare i dati dalla landing zone alla clean zone. Non fa altro, ma ho preferito tenerla separata perché mi sarà più facile implementare nuove modifiche.
Lambda trasferimento dati navigazione
import boto3
def move_objects(source_bucket, source_folder, destination_bucket, destination_folder):
s3 = boto3.client('s3')
#list objects in the source folder
response = s3.list_objects_v2(Bucket=source_bucket, Prefix=source_folder)
#check if objects were found
if 'Contents' in response:
#move objects
for obj in response['Contents']:
if obj['Key'] == source_folder:#we don't want to delete the main folder, but only file sin it
pass
else:
source_key = obj['Key']
destination_key = source_key.replace(source_folder, destination_folder, 1)
copy_source = {'Bucket': source_bucket, 'Key': source_key}
s3.copy_object(CopySource=copy_source, Bucket=destination_bucket, Key=destination_key)
s3.delete_object(Bucket=source_bucket, Key=source_key)
def lambda_handler(event, context):
#specify where data is and where we want it to be
source_bucket = 'landing-zone-step-function'
source_folder = 'website-stats/past-data/' # Ensure source_folder ends with a '/'
destination_bucket = 'clean-zone-step-function'
destination_folder = 'website-stats/' # Ensure destination_folder ends with a '/'
move_objects(source_bucket, source_folder, destination_bucket, destination_folder)
return {
'statusCode': 200,
'body': 'All objects and subfolders from the source folder have been moved to the destination folder.'
}
Lambda trasferimento recensioni
import boto3
def move_objects(source_bucket, source_folder, destination_bucket, destination_folder):
s3 = boto3.client('s3')
# List objects in the source folder
response = s3.list_objects_v2(Bucket=source_bucket, Prefix=source_folder)
print(f"response: {response}")
# Check if objects were found
if 'Contents' in response:
# Move objects
for obj in response['Contents']:
if obj['Key'] == source_folder:#we don't want to delete the main folder, but just files in it
pass
else:
source_key = obj['Key']
destination_key = source_key.replace(source_folder, destination_folder, 1)
copy_source = {'Bucket': source_bucket, 'Key': source_key}
s3.copy_object(CopySource=copy_source, Bucket=destination_bucket, Key=destination_key)
s3.delete_object(Bucket=source_bucket, Key=source_key)
def lambda_handler(event, context):
source_bucket = 'landing-zone-step-function'
source_folder = 'reviews/past-data/' # Ensure source_folder ends with a '/'
destination_bucket = 'clean-zone-step-function'
destination_folder = 'reviews/' # Ensure destination_folder ends with a '/'
move_objects(source_bucket, source_folder, destination_bucket, destination_folder)
return {
'statusCode': 200,
'body': 'All objects and subfolders from the source folder have been moved to the destination folder.'
}
Step Function
Ecco che finalmente entra in gioco Step Function. Dato che devono attivarsi funzioni Lambda, Crawlers e notifiche SNS differenti, ho creato due automazioni distinte.
La prima è per i dati di navigazione.
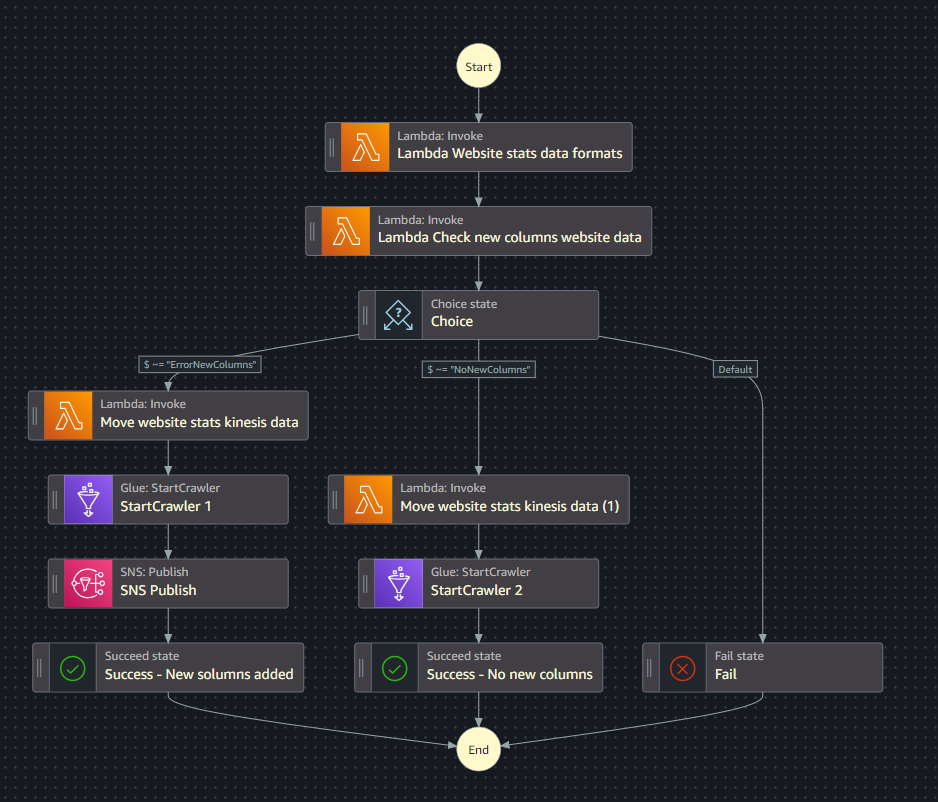
La seconda è invece per le recensioni.
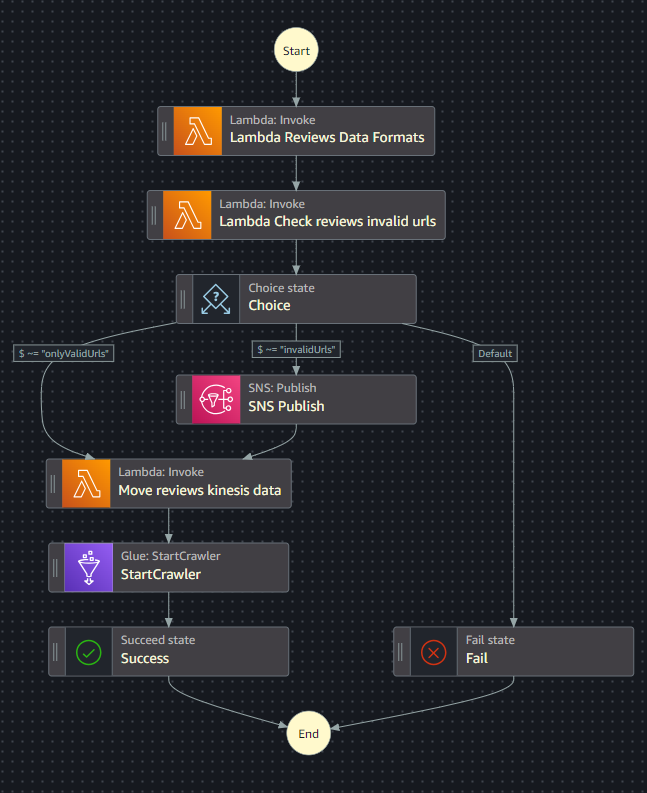
I crawler
I Glue Crawler di questo progetto vanno a scansionare le cartelle nella Clean zone nella loro totalità. Eh già, non è di certo il massimo andarsi a rileggere i dati che sono già stati caricati nel Glue Catalog. L’obiettivo di questo progetto è però l’approfondimento di Step Function e non la creazione di un crawler perfetto per l’occasione. Rimarrà così quindi, con la speranza di un futuro me talmente preciso che riandrà a ottimizzare questo crawler (non succederà mai).
Un punto debole di queste Step Function è il caso in cui ci siano più file in entrata, caricati in tempi molto ravvicinati. Si andranno infatti ad attivare 2 Step Function e la seconda andrà a richiedere l’accesso al Crawler che è già stato attivato però dalla prima.
In caso il crawler non abbia già finito il suo lavoro, la seconda Step Function terminerà con un errore perchè la risorsa crawler non è disponibile.
Power BI
Eccoci finalmente alla parte finale, quella in cui i dati vengono riassunti in dashboard sperando che siano anche utili a qualcuno.
Nella parte destra della schermata di Power Bi possiamo vedere come vengono categorizzati i dati importati da AWS. Le date vengono effettivamente viste come date e gli user_id vengono visti come numeri.
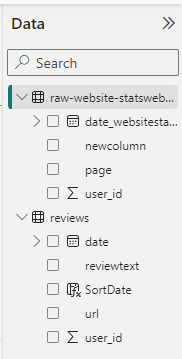
Nella tabella reviews trovate però una colonna nuova: SortDate.
L’ho dovuta creare per mettere in ordine cronologico discendente le recensioni ricevute dal sito web. In questo modo un eventuale ecommerce manager può trovarsi ogni mattina solamente le ultime, senza dover caricare anche recensioni vecchie.
Qui di seguito la piccola dashboard creata, prova che tutto funziona correttamente.
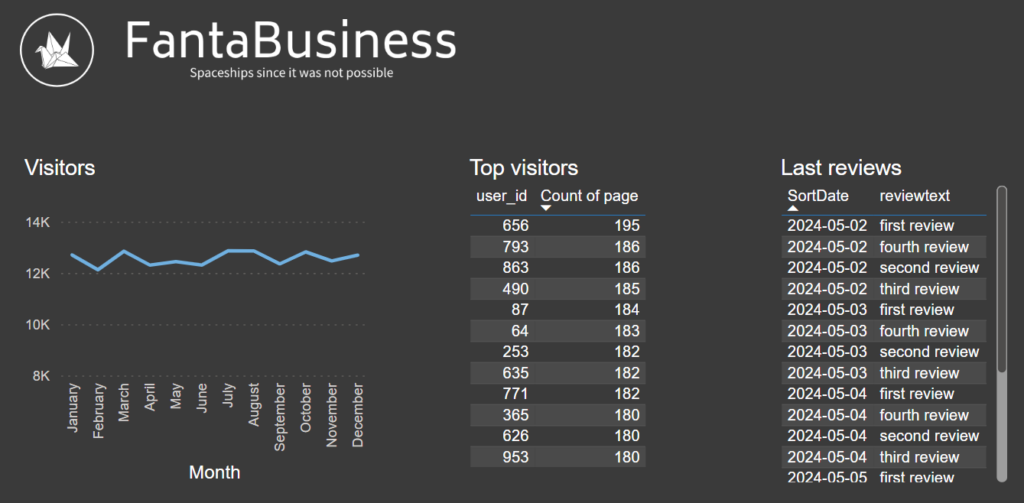
Così il progetto è finito! Step Function è uno strumento molto importante perchè permette di gestire al meglio i diversi servizi che AWS offre. Di sicuro le cose possono essere migliorate aggiungendo più controlli e automatizzando anche la pulizia dei dati, ma per ora mi fermo qui 😉.
Spero la lettura vi sia piaciuta e ci vediamo alla prossima.