In questo articolo andremo a vedere in che modo tabelle formattate con il metodo Apache Iceberg siano utili nella vita di ufficio.
Dati:
- Fittizi, creati con KDG nel precedente articolo dedicato a Step Function
Vantaggi:
- Time travel nei dati (quindi se qualcuno cancella qualcosa per sbaglio ha ancora possibilità di salvarsi)
- Maggiore efficienza delle query (spendiamo meno ogni mese per la lettura dei dati)
Creazione della tabella
Come prima cosa dobbiamo creare la tabella in formato Iceberg che ospiterà i nostri dati. Utilizziamo questa query in Athena.
Codice
CREATE TABLE cleanzonedb_iceberg.date_websitestats_second(
user_id bigint,
page string,
date_websitestats timestamp
)
PARTITIONED BY (month(date_websitestats))
LOCATION 's3://clean-zone-step-function/website-stats-iceberg/website-stats-second/'
TBLPROPERTIES ('table_type' = 'ICEBERG', 'format' = 'parquet')
Come colonna di partizionamento ho scelto la month(date_websitestats), quindi il mese(e anche l’anno) in cui le persone hanno visitato il sito web. Mi immagino infatti che la maggior parte delle query userà il mese come primo filtro.
Preparazione dei dati
Per comodità utilizzo gli stessi dati usati per un altro articolo. In questo modo mi è sufficiente usare Athena per copiare i dati dalla tabella originale a quella Iceberg.
Codice
insert into cleanzonedb_iceberg.date_websitestats
SELECT * FROM "marketing-agency"."raw-website-statswebsite_stats"
File nella cartella S3
Il valore aggiunto del salvare i dati con il metodo Iceberg sta nei metadati. Grazie a queste informazioni aggiuntive è come se avessimo a disposizione dei riassunti sui dati effettivi che andremo a leggere. Ad essere precisi, avremo a disposizione anche i riassunti dei riassunti dei riassunti (metadata.json che punta solo al giusto manifest list file che punta solo ai giusti manifest file che punta solo ai giusti dati). Inoltre tutti questi riassunti vengono catalogati in ordine cronologico, cosicché se volessimo sapere lo stato dei dati di settimana scorsa, ci basterà andarci a trovare quel riassunto.
Per un approfondimento vi lascio al seguente video, fatto molto bene da IBM.

Ogni volta che i dati nella tabella iceberg vengono modificati in qualche modo, anche i metadati si aggiornano per tenere traccia delle modifiche effettuate.
In modo generale possiamo dire che ogni modifica viene rispecchiata da un nuovo file json creato nella cartella /metadata/.
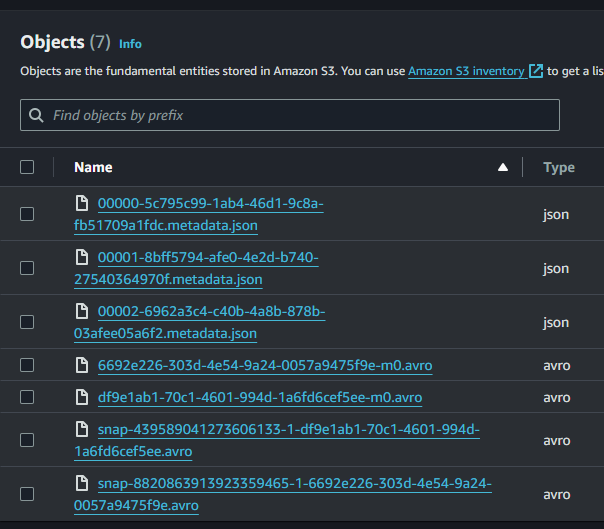
Nello screenshot sopra potete vedere 3 file, che iniziano rispettivamente per 00000…json, 00001…json e 00002…json.
Il primo file rappresenta il momento della creazione della tabella, il secondo file è una piccola importazione dei dati che ho fatto per testare il funzionamento della Step Function, mentre il terzo file è l’importazione di un intero anno di dati di navigazione.
Necessariamente è passato del tempo tra la seconda e la terza operazione, perciò ci è possibile testare il vantaggio del time travel.
Vantaggio 1: i viaggi nel tempo
Abbiamo preso in mano un nuovo progetto e vogliamo sapere come si sono evoluti i dati nel tempo? Abbiamo fatto un errore madornale con una query che era meglio non lanciare e non vogliamo essere licenziati? In questi casi i metadati delle tabelle iceberg ci vengono in nostro aiuto.
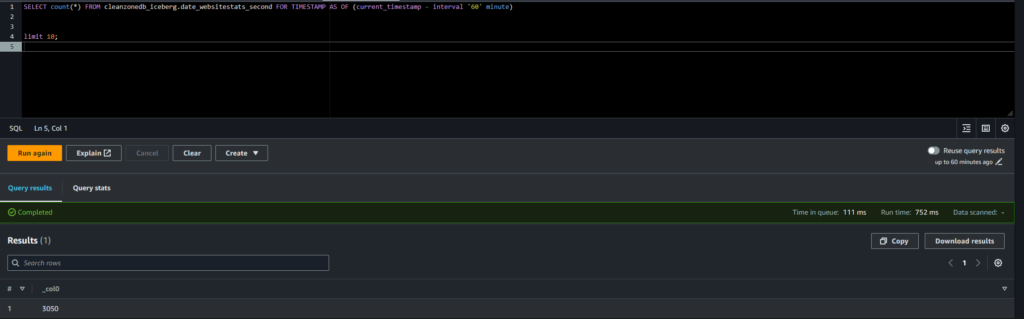
Basterà infatti aggiungere alla query l’indicazione del periodo per cui vogliamo leggere i dati. Scegliamo di quanti minuti o giorni vogliamo tornare indietro ed ecco che abbiamo il risultato.
In questo primo screenshot vediamo che c’erano poco più di 3000 righe dopo la prima importazione.
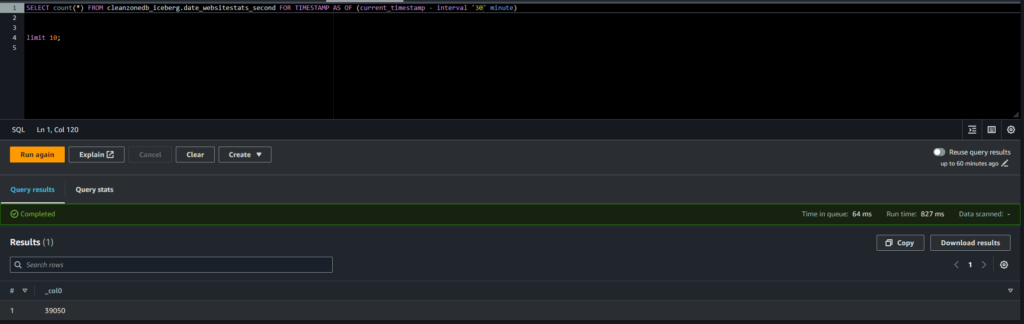
Qui invece vediamo che dopo la seconda importazione ce ne erano più di 30000
Vantaggio 2: query ottimizzate
Proprio per tutte le informazioni che le tabelle Iceberg hanno nei loro metadati, Athena può leggere i dati già avendo una buona idea di dove andarli a cercare.
Questo lo possiamo andare a vedere tramite l’ammontare dei dati letti per singola query. Possiamo fare questo confronto usando i dati della landing zone (semplice cartella S3 con dati in formato CSV) e i dati nella clean zone all’interno della tabella Iceberg.
Vado a leggere i dati relativi solo ad uno specifico giorno. Con i dati non ottimizzati devo leggere 2MB di dati per ottenere l’informazione che voglio.
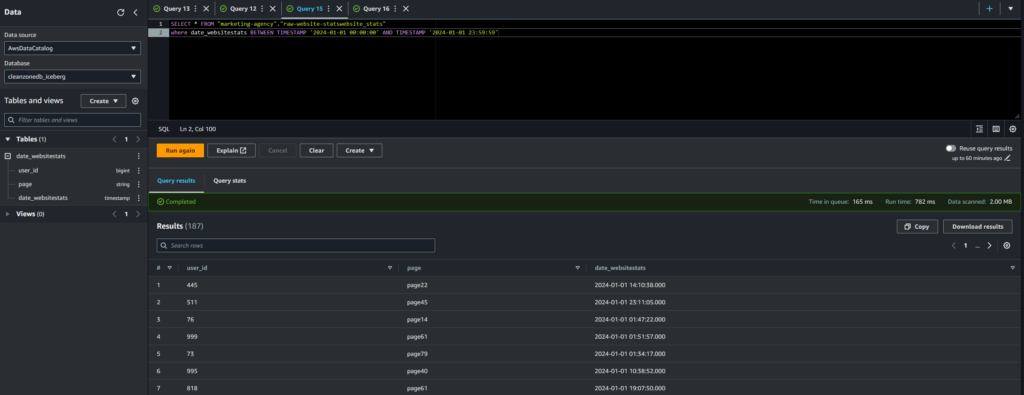
Con i dati formattati secondo il metodo Iceberg, per ottenere lo stesso risultato ho bisogno di leggermi solo 47,64KB.
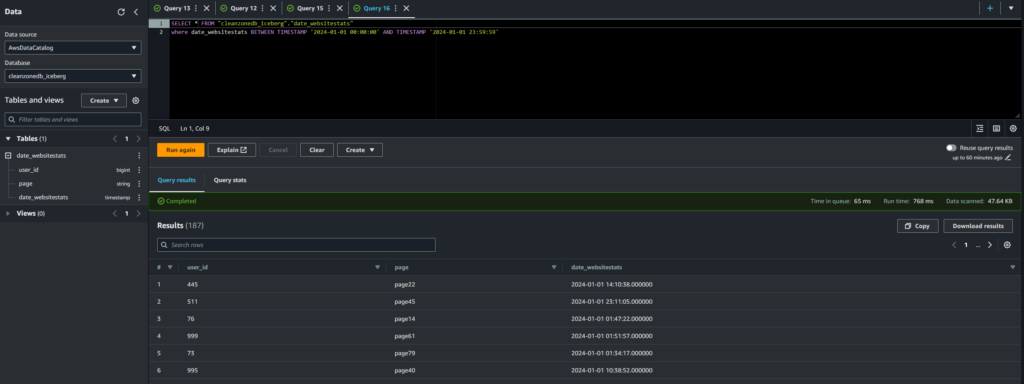
Se pensiamo a volumi di dati molto maggiori che potrebbero essere presenti in un’azienda, vediamo subito quanto questo può farci risparmiare in termini di costi di AWS.
Anche per questo breve articolo è tutto. Spero riusciate a mettere da parte qualche soldo con le tabelle Iceberg e di evitare disastri in ufficio per cancellazioni non volute.