L’EDA (Exploratory Data Analysis) è l’ analisi iniziale di un dataset. Sono i primi passi fatti per prendere confidenza con i nuovi dati che abbiamo a disposizione. Tramite semplici grafici e qualche riga di codice, ci addentreremo in una terra al momento sconosciuta e da bravi esploratori ne delineeremo i confini e i principali punti di riferimento.
Seppur si utilizzino tecniche basilari in questa fase di analisi, l’EDA è uno step molto importante da cui dipende la qualità di tutti gli step successivi.
Certamente gli algoritmi di Machine Learning, Deep Learning o elaborati metodi di clusterizzazione sono più affascinanti e ci restituiscono una sensazione quasi “magica” quando li applichiamo.
Ma proprio come il sapore di un piatto servito non può prescindere dalla qualità degli ingredienti, l’utilità di un’ analisi di dati non può prescindere dalla qualità dei dati utilizzati
Ci dobbiamo quindi chiedere:
- Ci sono valori duplicati dove non dovrebbero esserci?
- Quanti valori mancanti ha il nostro dataset?
- Le variabili sono del tipo esatto (integer, string, boolean …)?
- Chi ha creato il dataset? Quando e come sono stati raccolti i dati?
Con questo e i prossimi articoli, voglio mostrarvi una mia semplice EDA con cui sono andato ad analizzare un dataset pubblico del Ministero dello Sviluppo Economico.
Il dataset contiene i prezzi dei carburanti di tutti distributori presenti in Italia. I dati sono richiesti per legge ai proprietari degli impianti e sono disponibili in formato CSV.
La raccolta di queste informazioni è iniziata nel 3 Marzo 2015. Nel download sono però disponibili solo i dati del giorno precedente a quello di pubblicazione.
Vantaggi:
- Possono trarre vantaggio da questo dataset tutti gli attori della filiera dei carburanti in Italia. Sapere a che prezzo è disponibile il prodotto finale permette maggiore concorrenza tra i vari attori presenti sul mercato (ed, in teoria, un conseguente abbassamento del prezzo medio per il consumatore), ma permette anche ai diversi intermediari di adattarsi conseguentemente ai cambiamenti del mercato
Dati:
- 2 file CSV scaricabili da questo link https://www.mise.gov.it/index.php/it/open-data/elenco-dataset/carburanti-prezzi-praticati-e-anagrafica-degli-impianti
Schema EDA
Per rendere più facile la lettura, ho pensato che uno schema riassuntivo potesse aiutare. Perciò eccolo qui 👍
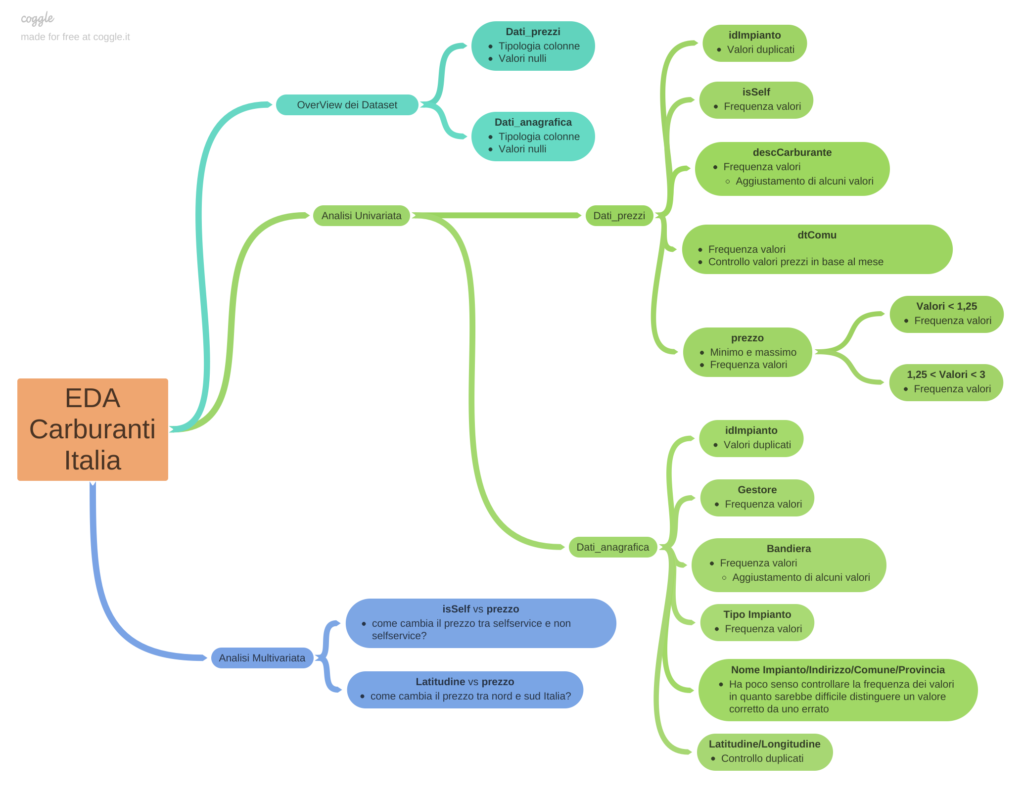
Overview del dataset
Prima di tutto importiamo i dati dai due CSV. In questo caso dobbiamo ricordarci di specificare il tipo di separatore. Di default si usa la virgola ma in questi file è stato usato il punto e virgola.
Codice
import pandas as pd
dati_prezzi = pd.read_csv("C:\\Users\David\Documents\Python Scripts\prezzo carburanti\dati\prezzo_alle_8.csv", sep=";")
dati_anagrafica = pd.read_csv("C:\\Users\David\Documents\Python Scripts\prezzo carburanti\dati\\anagrafica_impianti_attivi.csv", sep=";")
Utilizziamo quindi il metodo head() per avere una piccola overview di quelle che sono le prime 5 righe di entrambe le tabelle. È importante fare già delle supposizioni su quello che sarà il contenuto di ogni colonna. In questo modo potremmo verificare se le nostre ipotesi siano corrette o meno e, in caso ci fossimo sbagliati, avremmo modo di chiederci il “perché” siano state fatte delle scelte piuttosto che altre.
Codice
dati_prezzi.head()
| idImpianto | descCarburante | prezzo | isSelf | dtComu | |
|---|---|---|---|---|---|
| 0 | 6492 | Hi-Q Diesel | 1.6439999999999999 | 1 | 11/21/2022 15:00 |
| 1 | 6612 | Hi-Q Diesel | 1.669 | 1 | 11/21/2022 0:35 |
| 2 | 6484 | Hi-Q Diesel | 1.6739999999999999 | 1 | 11/21/2022 15:00 |
| 3 | 6503 | Hi-Q Diesel | 1.6759999999999999 | 1 | 11/21/2022 15:32 |
| 4 | 6632 | Hi-Q Diesel | 1.669 | 1 | 11/21/2022 0:35 |
- idImpianto: beh direi proprio che si tratta dell’indice identificatore di ciascun impianto all’interno del dataset. Forse sono solo numeri, perciò potrebbe essere un integer, ma potrebbe anche contenere stringhe
- descCarburante: la tipologia di questa colonna dovrebbe essere stringa. Anche se ci fossero dei carburanti identificati solamente da numeri, questi verrebbero salvati come sequenza di caratteri piuttosto che come integer o float dato che non dobbiamo eseguire operazioni matematiche su questi dati
- prezzo: data la presenza di valori decimali nei numeri di questa colonna, la sua tipologia dovrebbe essere float
- isSelf: da una colonna con questo nome mi immagino che i dati debbano rispondere alla domanda “is it self?” e che quindi le possibili risposte possano essere solo “Si” o “No”. Questa colonna dovrebbe essere quindi di tipo Boolean. Se così non fosse bisogna indagarne i motivi e la variabile diventerebbe una stringa
- dtComu: data in cui è stato comunicato il prezzo. Al momento c’è sia la data che l’orario. La colonna sarà di tipo date ma è da capire quale formato sia più conveniente per noi. Interessante il fatto che nel sito web del dataset è scritto che la comunicazione dei prezzi avviene alle 8:00 di ogni mattina, ma a quanto pare molte persone in Italia hanno orologi non funzionanti 😅
Vediamo ora l’altro CSV, dati_anagrafica:
Codice
dati_anagrafica.head()
| idImpianto | Gestore | Bandiera | Tipo Impianto | Nome Impianto | Indirizzo | Comune | Provincia | Latitudine | Longitudine | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 52829 | ERRA NICOLA | Api-Ip | Stradale | NaN | NaN | NaN | NaN | 40.716039000000002 | 14.941328 |
| 1 | 53637 | ODELLI LUCIA | Pompe Bianche | Stradale | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 52614 | FONZI PAOLO | Api-Ip | Stradale | stazione di servizio IP di Fonzi Paolo | via s francesco d'assisi snc - - | NaN | NaN | NaN | NaN |
| 3 | 53552 | KHALIL NOMAN | Agip Eni | Stradale | NaN | VIA LINCOLN 69 20092 | CINISELLO BALSAMO | NaN | NaN | NaN |
| 4 | 53906 | GE.CA.R SOCIETA' A RESPONSABILITA' LIMITATA SE... | Q8 | Stradale | NaN | VIA L.CAVALLARO SNC 84018 | SCAFATI | NaN | NaN | NaN |
Facciamo quindi delle ipotesi sulle tipologie delle colonne:
- IdImpianto: anche in questo caso ritengo molto probabile che questa colonna contenga solo numeri interi e che sia quindi di tipo Integer. Mi aspetto poi di poter unire i due CSV tramite questa colonna
- Gestore: qui dovrebbero essere presenti i vari nomi dei proprietari degli impianti. Quindi la tipologia dovrebbe essere stringa
- Bandiera: anche in questo caso dovrebbe essere una stringa in quanto la colonna rappresenta il brand del distributore
- Tipo di impianto: questa dovrebbe essere una variabile categoriale, perciò sarà di tipo stringa. È però da capire quante categorie sono presenti. Infatti anche le variabili Booleane possono essere viste come categoriali che possono avere solo 2 valori (come abbiamo visto nel caso di “isSelf”)
- Nome impianto: dovrebbe contenere i nomi dei vari impianti. Anche questa variabile sarà quindi ti tipo stringa. Dalla preview sopra notiamo come da questa colonna in poi siano presenti molti valori NaN (Not a Number). Sicuramente ne dovremo tener conto.
- Indirizzo/Comune/Provincia: queste colonne rappresentano la posizione geografica dell’ impianto in modo testuale. Saranno pertanto di tipologia stringa. Mi aspetto che concatenando questi 3 valori, all’interno del dataset non ci siano duplicati, altrimenti significherebbe che 2 impianti hanno la stessa posizione oppure che questi parametri non possono essere usati come chiave di ricerca
- Latitudine e Longitudine: sono le coordinate geografiche. Dato che sono numeri con decimali, la tipologia corretta per queste colonne è float. In caso ci siano alcuni valori non conformi, sono da modificare o eliminare. Come nel caso precedente, concatenando questi 2 valori mi aspetto di non trovare duplicati e che si possano usare come chiave di ricerca.
Controlli livello dataset
Dataset dati_prezzi
Dataset dati_prezzi Vediamo quindi come è stato impostato il dataset tramite questa riga di codice:
Codice
dati_prezzi.dtypes
Output:
idImpianto int64
descCarburante object
prezzo float64
isSelf int64
dtComu object
dtype: object
In Python, le colonne con tipologia str, quindi stringa, sono viste come di tipologia Object. Perciò, l’unica colonna la cui tipologia non è congruente con le nostre ipotesi è “isSelf”.
Avevamo ipotizzato boolean, ma invece è un integer. Vediamo velocemente quali dati contiene. Per fare questo possiamo utilizzare l’oggetto Counter, che andrà a controllare quali sono i diversi valori presenti in una lista e ci restituirà il numero di occorrenze di ciascun valore
Codice
from collections import Counter
Counter(dati_prezzi["isSelf"]).most_common()
Output:
[(1, 49600), (0, 41958)]
Sono presenti solo due valori, 1 e 0. Dato che questa variabile non può assumere altri valori (altrimenti si chiamerebbe qualcosa come “tipologia distributore” piuttosto che “isSelf”), è più opportuno cambiare la tipologia della colonna in boolean.
Codice
convert_dict = {'isSelf': bool}
dati_prezzi = dati_prezzi.astype(convert_dict)
print(dati_prezzi.dtypes)
Output:
idImpianto int64
descCarburante object
prezzo float64
isSelf bool
dtComu object
dtype: object
Una variabile di tipo boolean può avere solo 2 valori: True e False. Se ora andiamo a controllare i valori della colonna “isSelf” vediamo come questi siano stati convertiti.
Codice
Counter(dati_prezzi["isSelf"]).most_common()
Output:
[(True, 49600), (False, 41958)]
Controlliamo ora con che tipo di variabile sono salvate le date, quindi la colonna “dtComu”, all’interno del dataframe.
Codice
dati_prezzi.dtypes
Output:
idImpianto int64
descCarburante object
prezzo float64
isSelf bool
dtComu object
dtype: object
Le date sono salvate come stringhe. Python non ha infatti di default una tipologia di variabile per le date. Possiamo però risolvere questo problema importanto una libreria creata specificatamente per trattare questi oggetti.
Codice
from datetime import datetime
Convertiamo ora ogni valore della colonna “dtComu”
Codice
try:
for i in range(0,len(dati_prezzi["dtComu"])):
dati_prezzi["dtComu"][i] = datetime.strptime(dati_prezzi["dtComu"][i], "%d/%m/%Y %H:%M:%S")
except Exception as e: print(e)
dati_prezzi['dtComu']= pd.to_datetime(dati_prezzi['dtComu'])
Infine, andiamo a controllare che tutte le celle di questa colonna siano di tipo datetime.
Codice
z=[]
for elem in dati_prezzi["dtComu"]:
z.append(type(elem))
Counter(z).most_common()
Output:
[(pandas._libs.tslibs.timestamps.Timestamp, 91558)]
Ha funzionato!
Dataset dati_anagrafica
Vediamo ora le tipologie delle colonne del dataset dati_anagrafica.
Codice
dati_anagrafica.dtypes
Output:
idImpianto object
Gestore object
Bandiera object
Tipo Impianto object
Nome Impianto object
Indirizzo object
Comune object
Provincia object
Latitudine float64
Longitudine float64
dtype: object
In questo caso “IdImpianto” è salvata come stringa, quindi la convertiamo in Integer. Questo passaggio ci permetterà di evitare un problema di compatibilità tra colonne quando andremo ad unire i due dataset (eh già, indovinate chi ha sbagliato al primo tentativo? 😑 )
Codice
convert_dict = {'idImpianto': int}
try:
dati_anagrafica = dati_anagrafica.astype(convert_dict)
except Exception as e: print(e)
dati_anagrafica.dtypes
Output:
invalid literal for int() with base 10: '24895;SHABANI ENVER DISTRIBUTORE DI CARBURANTI E LUBRIFICANTI "API";Q8;Stradale;SHABANI ENVER DISTRIBUTORE DI CARBURANTI E LUBRIFICANTI "Q8";16 Adriatica Km. 285+460 sud - 60015;FALCONARA MARITTIMA;A
Otteniamo però un errore.
Significa che non possiamo convertire la nostra colonna da stringa a integer in quanto c’è almeno un valore che non può essere formattato come numero intero. Controllando nel dataset infatti, alla riga 466 osserviamo come il testo mostrato nell’errore sia tutto inserito all’interno della cella “idImpianto”. Dobbiamo scoprire ora quante righe hanno lo stesso problema. Per fare questo utilizziamo il costrutto try-except in modo da gestire in modo agile eventuali errori. Nel codice qui sotto stiamo chiedendo:
Prova a convertire in Integer ogni elemento di “idImpianto”. Quando trovi un elemento che non riesci a convertire, incrementa il contatore “x” di 1.
Codice
x=0
for elem in dati_anagrafica["idImpianto"]:
try:
int(elem)
except:
x += 1
x
Output:
181
L’ultima riga di codice stampa a video il valore di x, che in questo caso è 181. Non sono quindi molte le righe con questo problema, visto che la lunghezza del dataset è di 22154. Possiamo perciò semplicemente eliminarle.
Codice
y=[]
for elem in dati_anagrafica["idImpianto"]:
try:
int(elem)a
except:
y.append(dati_anagrafica[dati_anagrafica["idImpianto"] == elem].index[0])
In questo modo sarà molto semplice procedere con l’eliminazione, ci basterà utilizzare la seguente riga di codice:
Codice
update_dati_anagrafica = dati_anagrafica.drop(y)
Per essere sicuri che la modifica sia andata a buon fine, ricontrolliamo quante righe del dataset presentano questo problema.
Codice
x=0
for elem in update_dati_anagrafica["idImpianto"]:
try:
int(elem)
except:
z += 1
x
Output:
0
Il risultato è 0 💪
Andiamo finalmente ad aggiornare la tipologia della colonna.
Codice
convert_dict = {'idImpianto': int}
update_dati_anagrafica = update_dati_anagrafica.astype(convert_dict)
update_dati_anagrafica.dtypes
Output:
idImpianto int32
Gestore object
Bandiera object
Tipo Impianto object
Nome Impianto object
Indirizzo object
Comune object
Provincia object
Latitudine float64
Longitudine float64
dtype: object
La tipologia di “idImpianto” è ora int32 (nell’altro CSV questa variabile è un int64. Per semplicità ci fermiamo qui, altrimenti dovremmo importare la libreria “numpy”. Se vuoi saperne di più dai un’occhiata qui https://www.tutorialspoint.com/numpy/numpy_data_types.htm )
Valori nulli e duplicati – dati_prezzi
Una volta appurate e corrette le tipologie delle colonne, passiamo alla ricerca dei valori nulli tra i nostri dati. La funzione “info()” ci viene in grande aiuto.
Codice
dati_prezzi.info()
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 91558 entries, 0 to 91557
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 idImpianto 91558 non-null int64
1 descCarburante 91558 non-null object
2 prezzo 91558 non-null float64
3 isSelf 91558 non-null bool
4 dtComu 91558 non-null datetime64[ns]
dtypes: bool(1), datetime64[ns](1), float64(1), int64(1), object(1)
memory usage: 2.9+ MB
Vediamo subito come nel dataset dati_prezzi ci siano 91558 valori non null su 91558 righe del dataset. Siamo fortunati, in questo caso non ci sono righe da modificare o eliminare. Vedremo più avanti in dettaglio ciascuna colonna.
Controlliamo quindi se sono presenti valori duplicati. Questo controllo viene fatto prendendo in considerazione l’intera riga. Quindi, perchè si verifichi un valore duplicato bisogna che l’intera riga sia uguale ad un’altra riga.
Codice
print("valori duplicati dataset dati_prezzi: " + str((sum(dati_prezzi.duplicated()))))
Output:
valori duplicati dataset dati_prezzi: 0
Valori nulli e duplicati – dati_anagrafica
Passiamo quindi al secondo dataset.
Codice
update_dati_anagrafica.info()
Output:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 21973 entries, 0 to 22153
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 idImpianto 21973 non-null int32
1 Gestore 21972 non-null object
2 Bandiera 21973 non-null object
3 Tipo Impianto 21973 non-null object
4 Nome Impianto 21965 non-null object
5 Indirizzo 21971 non-null object
6 Comune 21970 non-null object
7 Provincia 21185 non-null object
8 Latitudine 21965 non-null float64
9 Longitudine 21965 non-null float64
dtypes: float64(2), int32(1), object(7)
memory usage: 1.8+ MB
In questo caso ci sono invece delle righe contenenti valori nulli. La colonna con più valori nulli è “Provincia”. Non sono tuttavia molti, ma il 4,37% ((22153-21185)/22153*100)
Ci sarebbero vari modi per tentare di recuperare queste righe: inserire i valori delle mode, i valori mediani o anche soluzioni di intelligenza artificiale per stimare i dati mancanti (recentemente Google ha implementato una funzionalità molto interessante in tal senso, ma sarà materiale di un altro articolo https://blog.tensorflow.org/2022/12/introducing-simple-ml-for-sheets.html )
In questo caso preferiamo semplicemente eliminare tutte quelle righe che contengono valori nulli. Per fare ciò, utilizziamo il seguente codice.
Codice
dati_anagrafica_cl = update_dati_anagrafica.dropna()
dati_anagrafica_cl.reset_index(drop=True, inplace=True)
Con la prima riga di codice andiamo ad eliminare tutte le righe all’interno del dataset che contengono ALMENO un valore nullo, mentre con la seconda ricalcoliamo l’indice delle righe.
Nello specifico, la funzione dropna() va a caccia dei valori:
- None
- Na (Not Available, dalla libreria Pandas)
- NaT (Not a Time, dalla libreria Pandas)
- NaN (Not a Number, dalla libreria Numpy)
Codice
dati_anagrafica_cl.info()
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 21178 entries, 0 to 21177
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 idImpianto 21178 non-null int32
1 Gestore 21178 non-null object
2 Bandiera 21178 non-null object
3 Tipo Impianto 21178 non-null object
4 Nome Impianto 21178 non-null object
5 Indirizzo 21178 non-null object
6 Comune 21178 non-null object
7 Provincia 21178 non-null object
8 Latitudine 21178 non-null float64
9 Longitudine 21178 non-null float64
dtypes: float64(2), int32(1), object(7)
memory usage: 1.5+ MB
L’output appena stampato ci conferma le modifiche appena apportate.
Controlliamo adesso quante righe duplicate ci sono all’interno del dataset.
Codice
print("valori duplicati dataset dati_anagrafica_cl: " + str((sum(dati_anagrafica_cl.duplicated()))))
Output:
valori duplicati dataset dati_anagrafica_cl: 0
Anche in questo dataset non ci sono righe duplicate 💪
Il prossimo step dell’EDA è l’analisi di ogni variabile all’interno dei dataset che dobbiamo utilizzare, ma lo vedremo in un prossimo articolo (Link seconda parte: https://www.davidemarcon.com/eda-in-python-parte-2/)
Se hai consigli o richieste, commenta pure nel box che vedi qui sotto 👍