Immaginiamo di lavorare per un’ azienda di bike sharing. Il nostro servizio si basa sulla possibilità di noleggiare una delle nostre biciclette sparse per la città in specifiche stazioni.
Le persone potranno avere sempre una bicicletta in buono stato (in caso di guasti le andiamo a riparare sul posto) e non devono temere i furti perchè, in caso la bicicletta che hanno usato per il viaggio di andata sparisca, dovranno semplicemente noleggiarne un’ altra per il ritorno.
Per noi è quindi molto importante sapere quando una bicicletta è guasta, se ci sono punti della città in cui c’è molta richiesta di questo servizio o, viceversa, se ci sono zone in cui le nostre bicilette risulterebbero inutili.
Per tutto questo, possiamo usare i dati.
Possiamo infatti collegare ogni biciletta ad internet in modo da sapere:
- Tipologia di biciletta noleggiata (normale? elettrica? tandem? etc)
- Quante volte viene usata
- Il tragitto fatto
- Altre informazioni che possono essere utili all’ azienda
In questo articolo voglio mostrarvi uno spezzone del tragitto che fanno questi dati utilizzando la piattaforma Cloud AWS, nello specifico:
- Importazione dei file CSV con i dati
- Prima pulizia dei dati
- Qualche grafico per analizzare la situazione delle biciclette
Tutti i dati li potete scaricare gratuitamente qui.
Iniziamo!
Prima lettura dei dati
Il primo passo è capire bene che dati dobbiamo trattare. In questo caso sono tutti file CSV e ognuno di essi contiene i dati di un mese di noleggi. Questo sognifica che ci sarà un caricamento al mese. Decisamente una situazione tranquilla, siamo fortunati.
Quali dati troviamo all’ interno di ogni CSV?
- ride_id: è il codice univoco associato a ciascuna corsa
- rideable_type: tipologia di bicicletta noleggiata
- start_station_id: contiene il codice della stazione in cui è stato fatto partire il noleggio
- end_station_id: contiene il codice della stazione in cui il noleggio è terminato
- start_station_name: contiene il nome della stazione da cui è stato fatto partire il noleggio
- end_station_name: contiene il nome della stazione in cui il noleggio è terminato
- start_lat, end_lat, start_lng, end_lng: queste sono le coordinate georgafiche di dove il noleggio è iniziato e finito
- member_casual: informazioni sulla tipologia di iscrizione della persona. può essere un “member” (con abbonamento annuale) o un cliente “casual” (noleggio singolo o giornaliero del mezzo)
Possono essere utili questi dati per la nostra azienda?
Beh sicuramente conoscere le stazioni di partenza e di fine corsa ci aiuterà a capire quali sono le zone in cui le nostre biciclette sono più richieste e in quali invece possiamo diminuire l’ offerta. Una bella mappa potrebbe aiutarci a prendere decisioni più efficaci.
Possiamo poi capire quale sia la tipologia di bicicletta più utilizzata e la lunghezza media delle tratte percorse. Queste informazioni potrebbero essere utili nel momento in cui dobbiamo investire per l’acquisto di nuove biciclette per la nostra flotta.
Infine, nella descrizione dei dati si riporta che i clienti “member” sono più profittevoli rispetto a quelli “casual”. Possiamo quindi attivare specifiche comunicazioni e promozioni per aumentare il numero di utenti che sottoscrivono un abbonamento annuale.
Idea di progetto
Per questo progetto useremo AWS, una popolare piattaforma per la gestione dei dati in cloud.
Qui di seguito lo schema di ciò che andremo a fare:
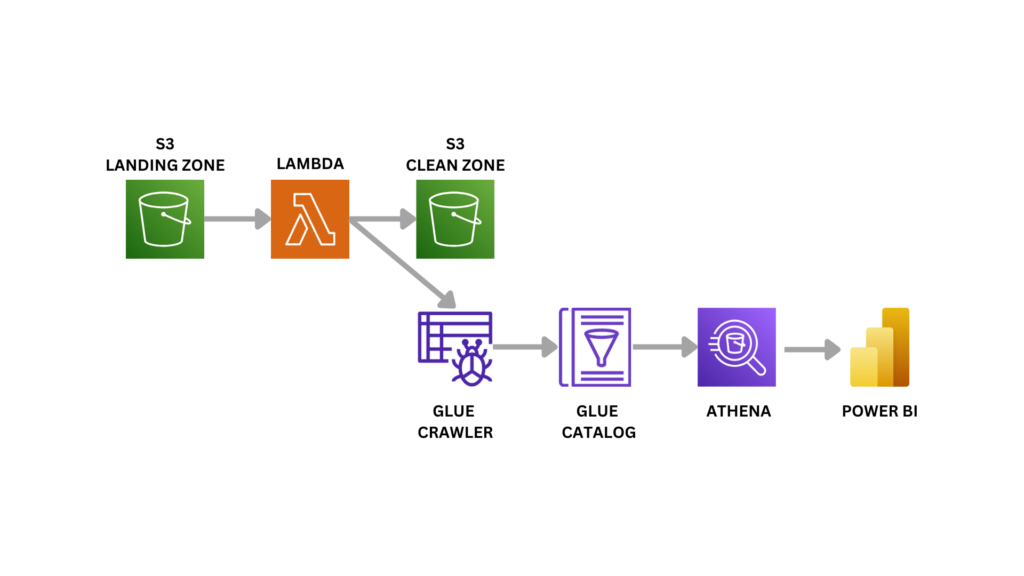
Come prima cosa ci servirà un contenitore per caricare i file CSV che riceviamo in input. Questo magico posto sarà il nostro primo S3 bucket.
Tramite una funzione Lambda, andremo poi a fare dei controlli qualitativi: eliminare valori nulli o controllare errori di misurazione.
Una volta finiti i controlli, i file “ripuliti” andranno caricati in un altro S3 Bucket e verrà attivato un Glue Crawler che si andrà a leggere questi file, caricandoli in una tabella di Glue Catalog.
Il passo finale è analizzare questi dati. Utilizzeremo per questo il servizio AWS Athena collegato allo strumento esterno PowerBI.
Preparazione S3 Bucket landing-zone
Il primo passo è la creazione di un S3 Bucket da utilizzare come zona di landing per i dati grezzi, una sorta di zona scarico merci che dovranno poi però essere ben catalogate ed ordinate in un altro magazzino.
Accediamo quindi al servizio S3 della piattaforma AWS e creiamo un nuovo bucket dandogli un nome ben chiaro.
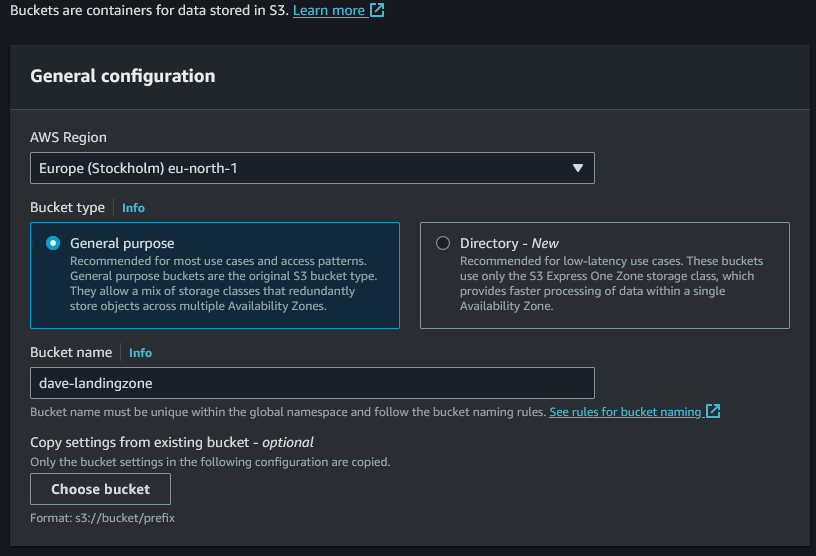
Lasciamo tutte le altre impostazioni così come sono e lo creiamo. Per una organizzazione più chiara dei file, creiamo poi una sotto cartella “bike-sharing” e poi una sotto-sottocartella “data”. Il percorso finale dove andremo a caricare i CSV sarà quindi questo: s3://dave-landingzone/bike-sharing/data/
Preparazione S3 Bucket clean-zone
Con lo stesso procedimento creiamo un altro S3 bucket da utilizzare come “clean-zone”, una zona dove la funzione Lambda caricherà i nostri dati dopo averli puliti.
Nella creazione delle sottocartelle, manteniamo la stessa logica che userà poi Glue, quindi ci sarà il livello Database e il sottolivello Table.
Il percorso di caricamento dei file ripuliti sarà questo:
s3://dave-clean-zone/bike-sharing/bike-sharing-database/bike-sharing-table/
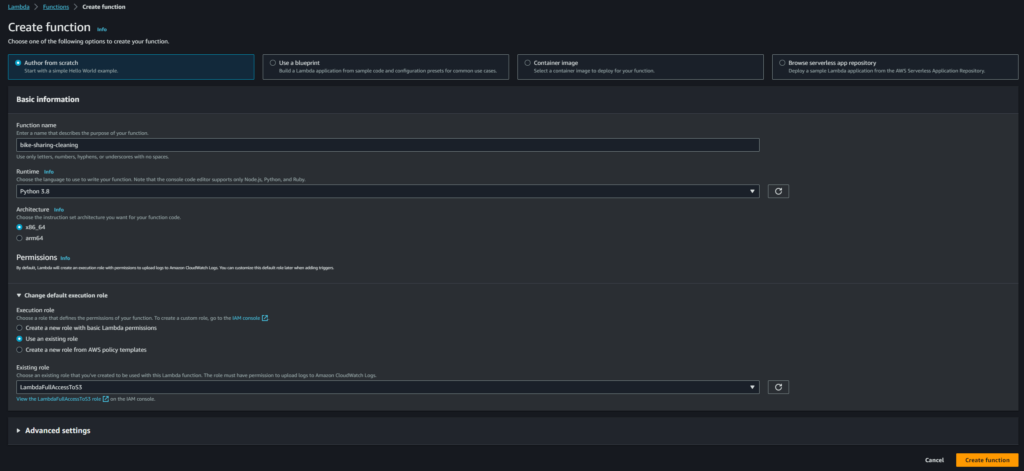
La funzione lambda
Andiamo a creare una nuova funzione chiamata bike-sharing-cleaning. Utilizziamo come runtime Python 3.10 e carichiamo il layer che ci permette di utilizzare la libreria pandas.

I giusti permessi per Lambda
Per fare in modo che la nostra funzione possa accedere alla landingzone e alla cleanzone dobbiamo darle i giusti permessi. Nei 3 Json che seguono possiamo vedere i permessi per:
- S3 —> ho utilizzato la policy “AmazonS3FullAccess” presente di default in AWS
- CloudWatch —> ho utilizzato la policy “AWSLambdaBasicExecutionRole” presente di default in AWS
- Glue Crawler —> in questo caso ho creato il Json da zero. Ho dato la possibilità alla funzione di inizializzare qualsiasi crawler a disposizione
Permessi S3
//Permessi S3
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*",
"s3-object-lambda:*"
],
"Resource": "*"
}
]
}
Permessi CloudWatch
//Permessi CloudWatch
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
Permessi AWS Glue Crawler
//Permessi AWS Glue Crawler
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "glue:StartCrawler",
"Resource": "*"
}
]
}
Ecco la nostra lambda appena creata:
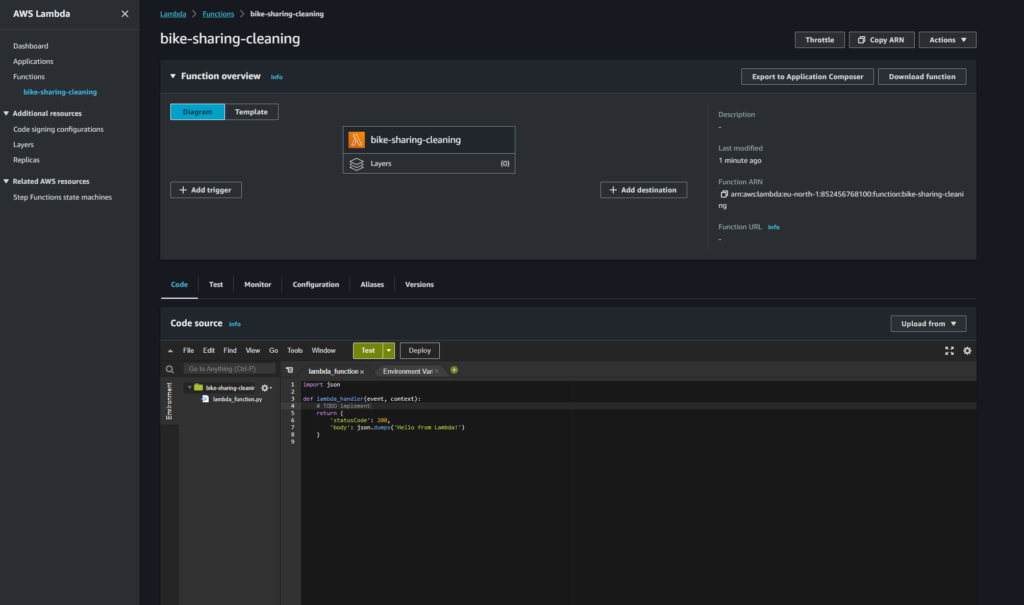
Trigger
Questa Lambda si deve attivare ogni qualvolta che un file CSV con i nostri dati viene caricato nella cartella all’ interno dell’S3 di landing che abbiamo creato. Dobbiamo creare quindi un trigger per fare questo.
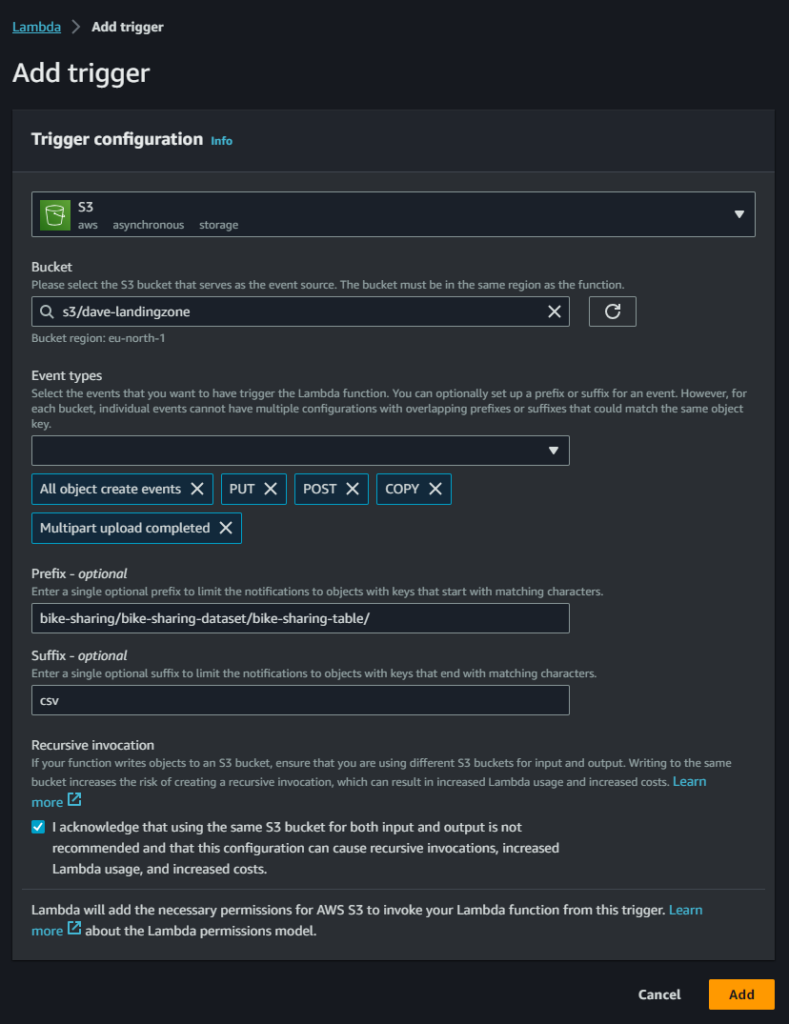
Nella schermata principale della funzione facciamo clic su “Add Trigger”. Nella schermata che segue andiamo a definire la natura dell’ evento che fa attivare la funzione. Selezioniamo quindi il servizio S3 e specifichiamo il bucket a cui ci stiamo riferendo.
Gli eventi scatenanti sono tutti gli eventi di upload di file: selezioniamo tutte le tipologie di creazione di file disponibili.
Sono presenti poi due raffinamenti per questo trigger:
- Prefix —> nel caso il bucket di landing sia condiviso tra più progetti, probabilmente non vogliamo che tutti i file caricati, indipendentemente dalla destinazione, attivino la nostra funzione. In questo caso allora possiamo specificare quale cartella e sotto cartella deve essere monitorata da questo trigger.
- Suffix —> In questa nostra sottocartella potremmo caricare qualsiasi tipo file. Immagini, video, testo, ecc. Per questo nostro progetto ci interessano solamente i file CSV.
Codice della lambda
Prima di scrivere il codice della nostra funzione dobbiamo capire cosa vogliamo che faccia.
Per fare questo andiamo ad aprire in un notebook Python uno dei diversi CSV a nostra disposizione e ne osserviamo i dati al suo interno.

Da qui non vedo alcuna colonna particolarmente problematica o poco utile.
Controlliamo la presenza di valori nulli nelle colonne.
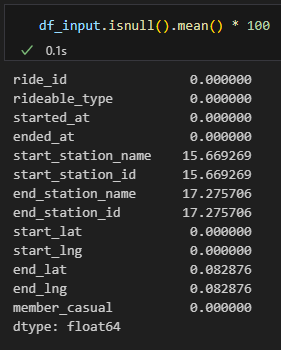
6 colonne hanno valori nulli al loro interno, con un massimo del 17.26% per gli identificativi delle stazioni di fine corsa. Siamo sicuri che sia un errore? Potrebbe essere che le stazioni di inizio e fine corsa siano inferite dai dati di longitudine e latitudine e che quindi un valore nullo in queste colonne significhi che la bicicletta sia stata parcheggiata lontana da una delle stazioni. Ci sono valori nulli anche tra le coordinate geografiche di fine corsa. Cosa accade quando una bicicletta viene parcheggiata in un luogo in cui i sensori non riescono a determinarne le coordinate (ad esempio all’interno di una galleria o in un parcheggio coperto)?
Queste sono tutte domande molto importanti quando si vanno a implementare soluzioni automatiche per i dati. Il nostro lavoro qui è aiutare l’ azienda ad estrapolare più valore possibile da queste informazioni e a volte la mancanza di informazioni è un informazione molto importante.
Questo articolo di blog vuole descrivere una semplice implementazione di AWS, perciò sorvolerò su questo problema e semplicemente elimino ogni riga che ha almeno un valore nullo (ah che bello evitare i problemi 🏖️).
La prima colonna contiene i valori chiave, quindi identificatori univoci. Controlliamo velocemente che sia effettivamente così.
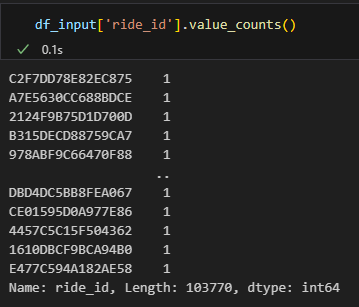
Tutto regolare, non ci sono valori duplicati.
Controlliamo ora i valori delle coordinate geografiche. Per capire di quanto varino utilizziamo un boxplot.
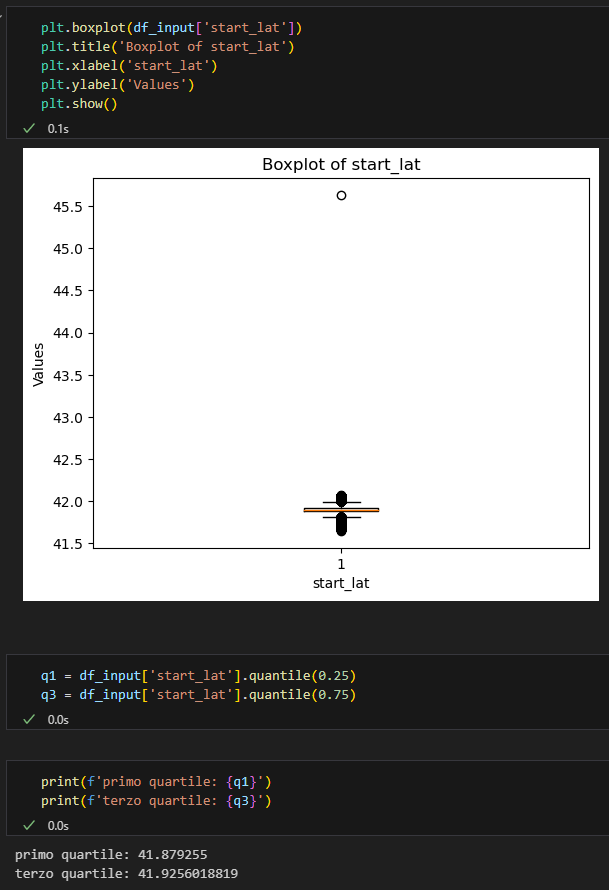
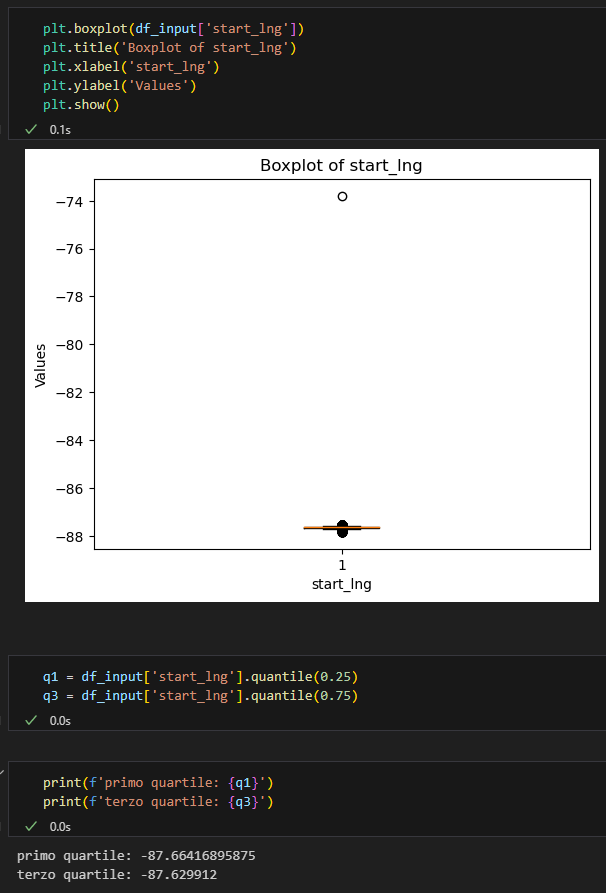
Anche in questo caso dovremmo chiederci quali siano i valori interessanti per le analisi dell’ azienda. Cosa significano gli outliers? Sono biciclette parcheggiate in luoghi non idonei? Sono sensori malfunzionantie che quindi devono essere riparati?
Come prima, dato che il principale tema di questo articolo è AWS e le sue funzioni, mi semplifico la vita e semplicemente elimino gli outliers.
Cosa deve quindi fare la nostra funzione lambda?
- Rimuovere le righe con almeno un valore nullo
- Rimuovere le righe relative agli outliers delle colonne start_lat e start_lng
Scrittura del codice della funzione Lambda
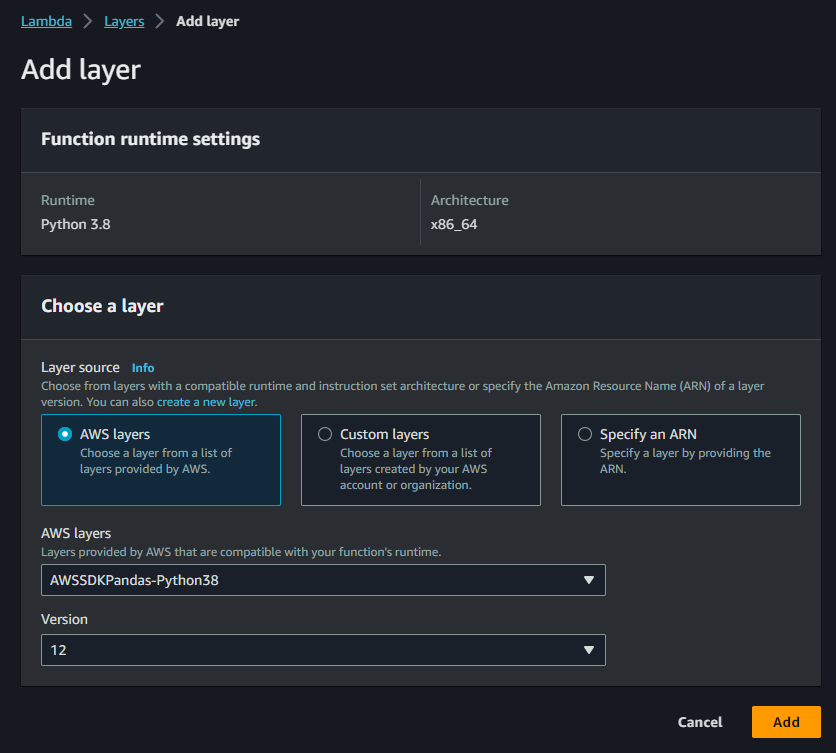
Per manipolare e pulire i dati utilizzeremo la libreria pandas. Per fare questo dobbiamo importare nella funzione Lambda un “layer” che contiene questa libreria.
Nella dashboard clicchiamo quindi su “Layers” e quindi su “Add Layers”.
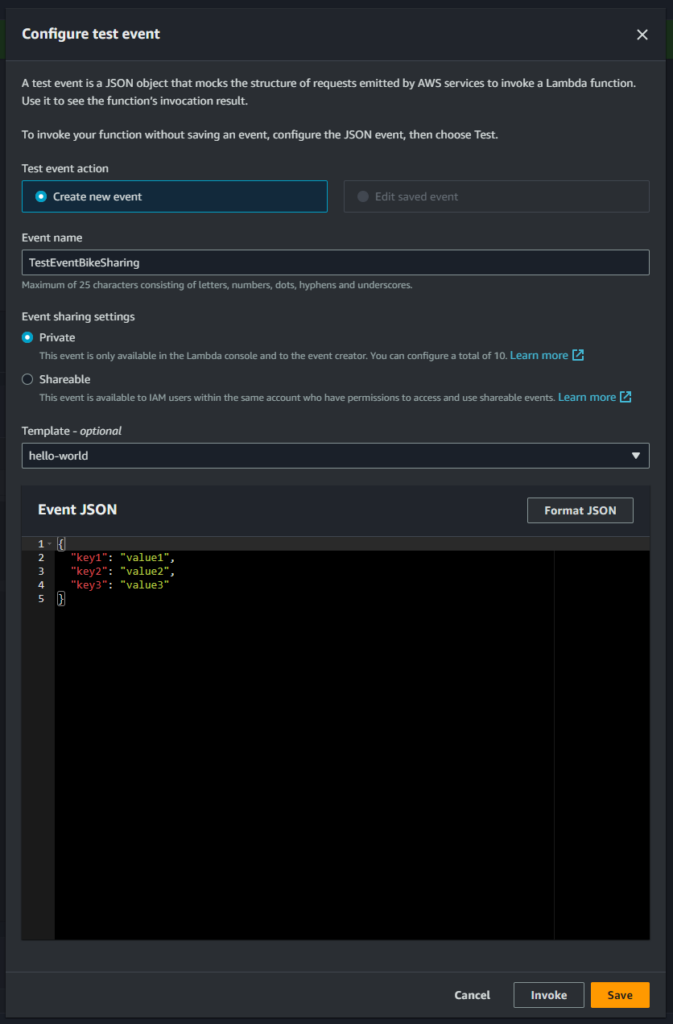
Per eseguire dei test nello sviluppo, AWS ci lascia creare un evento di test che verrà poi passato alla funzione. Per rendere il tutto più facile e veloce, come prima cosa facciamo in modo che la funzione ci restituisca in output esattamente ciò che lei riceve in input. Possiamo caricare un file tra quelli che abbiamo a disposizione ed ottenere in risposta il Json specifico di quel caricamento. Utilizzeremo questo Json come evento di test per simulare futuri caricamenti.
Per fare questo dobbiamo prima creare un evento di test base, come nell’immagine che segue.
Utilizziamo poi questo codice nella lambda:
Codice
import json
def lambda_handler(event, context):
print(event)
return event
Salviamo la funzione e carichiamo il nostro primo csv. In questo modo avremo in output il parametro “event” della nostra lambda” e potremmo sviluppare il resto della funzione.
Ecco che abbiamo il nostro Json, bello pronto nell’output della funzione (nella tab di output di Lambda o in Cloudwatch). Riapriamo l’evento di test e inseriamo questo al posto delle poche righe presenti.
Json evento test
{
"Records":[
{
"eventVersion":"2.1",
"eventSource":"aws:s3",
"awsRegion":"eu-north-1",
"eventTime":"2023-11-26T15:28:06.156Z",
"eventName":"ObjectCreated:CompleteMultipartUpload",
"userIdentity":{
"principalId":"AWS:AROA4M6TCAJSLGFX4WYHZ:DavideTerzoUtente"
},
"requestParameters":{
"sourceIPAddress":"178.85.29.127"
},
"responseElements":{
"x-amz-request-id":"QAXD8AS4VH4X5W7D",
"x-amz-id-2":"QMRaGNGklNgeKUPMSLnepX1i6fVlFLNVYM1wXsQxGR2xE6D06w2NKKDIGaDYbbSEgvBFgO6WwrXrhGaSKdRoiA80u/8Mo65H"
},
"s3":{
"s3SchemaVersion":"1.0",
"configurationId":"5fb1c2b5-d3e8-4f79-8ae1-e5cc36edbad6",
"bucket":{
"name":"dave-landingzone",
"ownerIdentity":{
"principalId":"A1SXH770K8BZWS"
},
"arn":"arn:aws:s3:::dave-landingzone"
},
"object":{
"key":"bike-sharing/bike-sharing-dataset/bike-sharing-table/202201-divvy-tripdata.csv",
"size":19011955,
"eTag":"ee4f9f4cc4595f378a0e9fa65d4899db-2",
"sequencer":"00656363FFF577B73B"
}
}
}
]
}
Possiamo ora dedicarci allo sviluppo effettivo della funzione. per semplicità incollo di seguito già tutto il codice della Lambda.
Codice
import boto3
import awswrangler as wr
import io
from io import StringIO
import pandas as pd
client = boto3.client('glue')
def lambda_handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
s3_client = boto3.client('s3')
response = s3_client.get_object(Bucket=bucket, Key=key)
content = response['Body'].read().decode('utf-8')
df_input = pd.read_csv(io.StringIO(content))
#eliminiamo le righe che contengono valori nulli
df_input = df_input.dropna()
#eliminiamo gli outliers per la colonna start_lat
q1 = df_input['start_lat'].quantile(0.25)
q3 = df_input['start_lat'].quantile(0.75)
iqr = q3 - q1
#calcoliamo la lunghezza dei baffi del boxplot
whisker_length = 1.5 * iqr
#calcoliamo i punti finali dei baffi del boxplot
lower_whisker = q1 - whisker_length
upper_whisker = q3 + whisker_length
df_input = df_input.loc[(df_input['start_lat'] >= lower_whisker) & (df_input['start_lat'] <= upper_whisker)]
#facciamo la stessa cosa per la colonna start_lng
q1 = df_input['start_lng'].quantile(0.25)
q3 = df_input['start_lng'].quantile(0.75)
iqr = q3 - q1
#calcoliamo la lunghezza dei baffi del boxplot
whisker_length = 1.5 * iqr
#calcoliamo i punti finali dei baffi del boxplot
lower_whisker = q1 - whisker_length
upper_whisker = q3 + whisker_length
df_input = df_input.loc[(df_input['start_lng'] >= lower_whisker) & (df_input['start_lng'] <= upper_whisker)]
#ora definiamo il percorso per la scrittura del csv output, convertiamo il dataframe e lo carichiamo nella destinazione
#prima dobbiamo ottnere il nome del file di input in modo da utilizzarlo anche come file di output
key_list = key.split("/")
output_path = 's3://dave-clean-zone/bike-sharing/bike-sharing-database/bike-sharing-table/'+key_list[-1]
print(output_path)
wr.s3.to_csv(df_input, output_path, index=False)
response = client.start_crawler(Name='bike-sharing-crawler')
return 0
Difatto la nostra funzione fa esattamente quanto abbiamo menzionato prima. Come prima cosa va a prendersi il CSV nella landing-zone e lo legge come pandas dataframe. Va poi a cancellare tutte le righe che contengono anche un solo valore nullo e gli outliers delle coordinate geografiche.
Va poi a riconvertire il pandas dataframe in CSV e lo carica nella clean-zone. Come ultima cosa aziona il crawler di AWS Glue per fare in modo che i dati possano essere analizzati con il servizio Athena.
Un punto debole di questa funzione è che se il crawler è già attivo perchè è da poco stato caricato un altro file, la funzione ci restituirà un errore. Ma non andrò a gestire questa casistica (o almeno non in questo articolo) per 2 motivi:
- Il crawler va a vedersi ogni volta tutta la cartella, quindi basterà aspettare un nuovo caricamento di file (anche questa parte potrebbe essere ottimizzata ulteriormente)
- I file contengono un mese di dati ciascuno, perciò verosimilmente anche i caricamenti saranno mensili. Dato che il crawler impegna qualche minuto per scansionare la cartella, è poco probabile che venga attivato 2 volte in poco tempo.
Creazione del crawler in Glue
Glue è un servizio di AWS che al suo interno contiene più sottoservizi. Uno di questi sono i crawler e servono per scansionare delle specifiche cartelle e a estrapolare i metadata dei file al loro interno.
In parole povere, vanno a vedersi i file di dati e cercano di capire i nomi e le tipologie delle colonne al loro interno. Grazie a queste informazioni possiamo procedere poi con Athena.
Ma come si crea un crawler?
Accediamo al servizio Glue, andiamo nella tab “Crawler” nel menù a sinistra e clicchiamo sul bottone “Create crawler” in alto a destra.
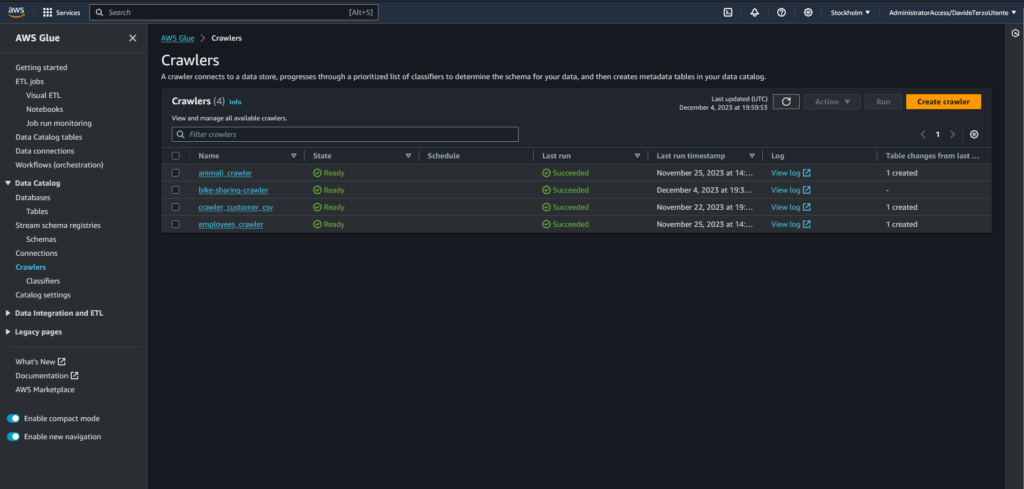
Vediamo ora i 5 step della creazione di un crawler. Sono molto semplici e veloci.
Primo step: qui andremo a definire il nome del crawler. Deve essere lo stesso specificato anche all’ interno della funzione Lambda.
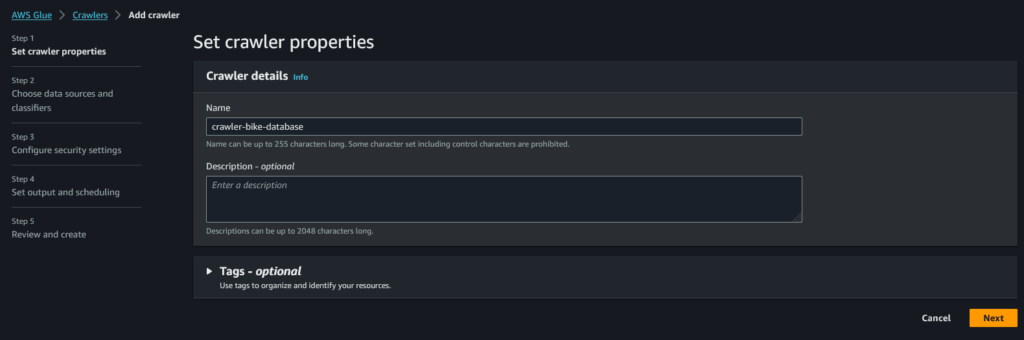
Secondo step: qui selezioniamo la cartella che il crawler deve scansionare. Nel nostro caso s3://dave-clean-zone/bike-sharing/bike-sharing-database/bike-sharing-table/
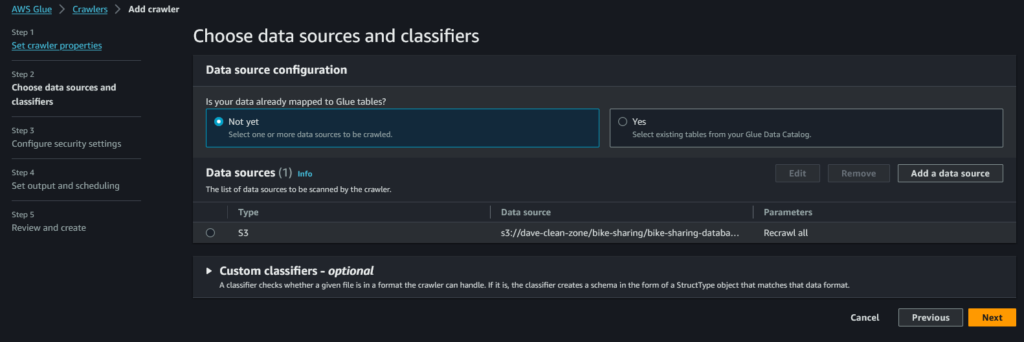
Terzo step: diamo al crawler i permessi di cui ha bisogno. Interagisce con 3 servizi:
- S3: il crawler deve avere la possibilità di entrare nel S3 bucket relativo alla nostra clean-zone
- Glue: una volta scansionati i dati, dovrà accedere a Glue per creare o aggiornare database e tabelle
- Cloudwatch: deve poter caricare i suoi log di riuscita/fallimento in Cloudwatch
Qui di seguito il Json del ruolo associato al crawler:
Ruolo del crawler
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:UpdateTable",
"glue:CreateTable"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::dave-clean-zone"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::dave-landingzone/bike-sharing/data/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:eu-north-1:852456768100:log-group:/aws-glue/crawlers",
"arn:aws:logs:eu-north-1:852456768100:log-group:/aws-glue/crawlers:log-stream:bike-sharing-crawler"
]
}
]
}
Quarto step: andiamo a selezionare il database di Glue Catalog in cui il crawler caricherà i dati. Lo farà all’ interno di una tabella e con Athena andremo a interrogare esattamente questa.
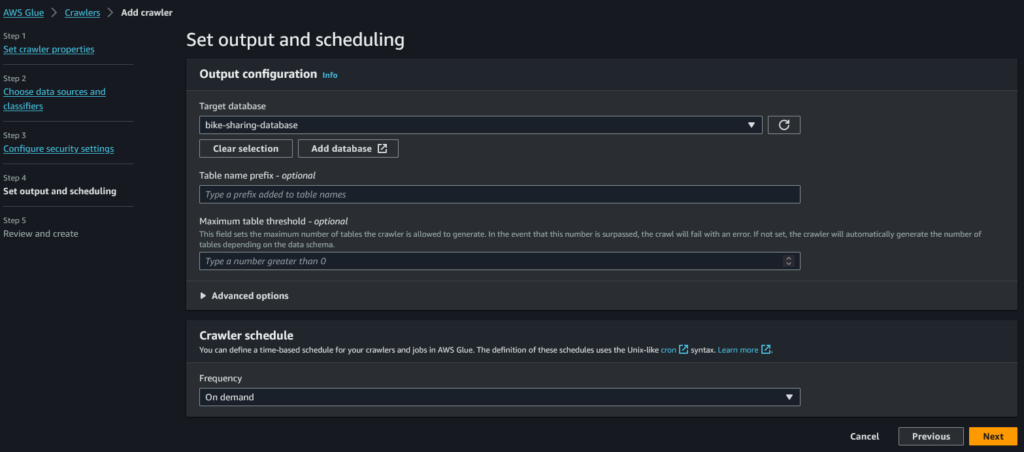
Quinto step: rivediamo quanto scelto e clicchiamo su “Create crawler”
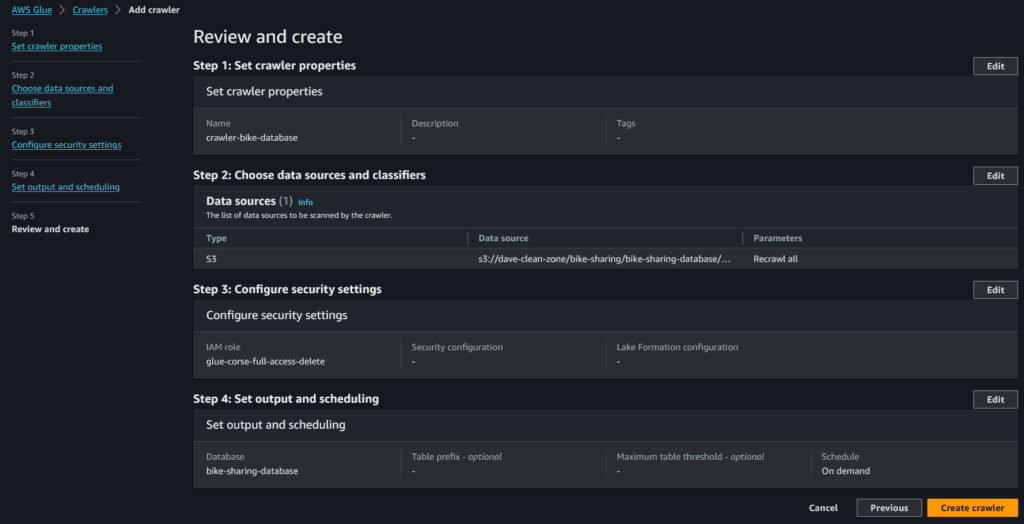
Caricamento dei dati
Ora è tutto pronto per il caricamento dei dati all’interno del primo bucket che abbiamo creato, quello usato come “landing-zone”.
Caricando manualmente i csv, potremo vedere dalla dashboard dei crawler di Glue il nostro crawler attivarsi.
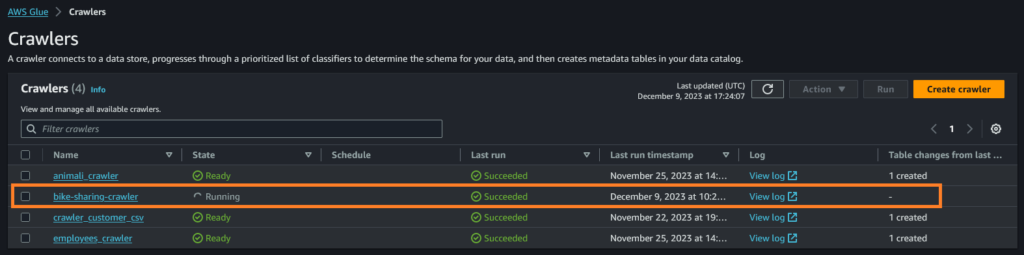
Una volta terminato di caricare tutti i file, li possiamo analizzare con Athena e PowerBI.
Analisi dati con Athena e PowerBI
Per creare una Dashboard riassuntiva uso il programma esterno PowerBI. Perché non utilizzo il servizio di AWS QuickSight? Perché PowerBI è gratuito mentre per QuickSight devo pagare un abbonamento 💸 .
Dovrò pagare solamente le query di Athena ma per i pochi dati che ho utilizzato in questo articolo probabilmente rientro nella FreeTier di AWS.
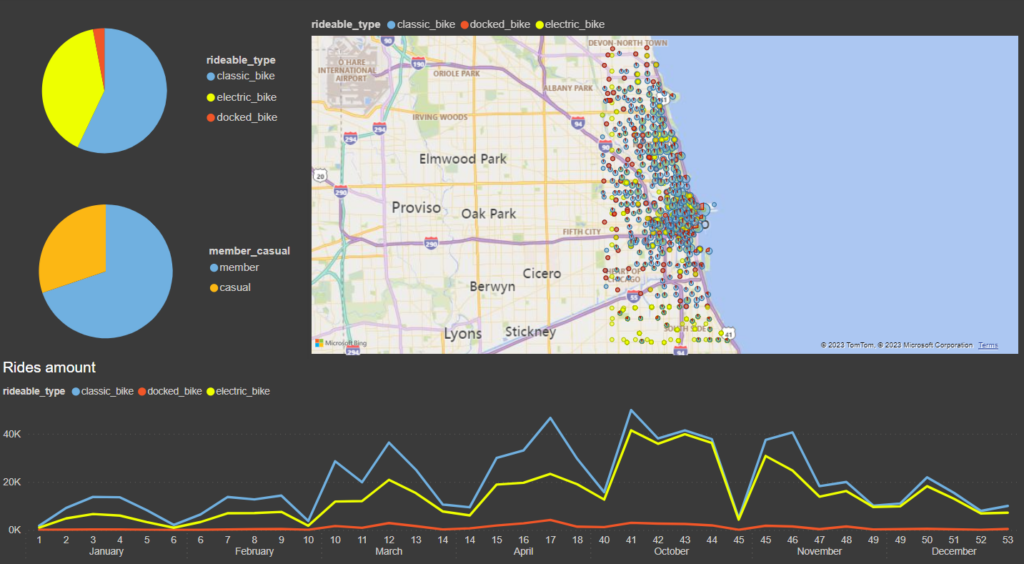
Ecco la Dashboard che ho creato. Vediamo che le biciclette più noleggiate sono quelle classiche, tendenzialmente nella parte centrale e superiore di Chicago, mentre nell parte bassa vengono noleggiate sopratutto biciclette elettriche.
La maggioranza delle persone ha un abbonamento annuale.
Dal grafico in basso vediamo un forte calo dei noleggi nei mesi invernali e un picco di ordini a ottobre.
Chicago è anche una città turistica e secondo me è difficile che un turista sottoscriva l’ abbonamento annuale al nostro servizio di bike sharing. Quindi penso che la maggior parte dei noleggi degli utenti “casual” sia durante l’estate. Vediamo se è vero.
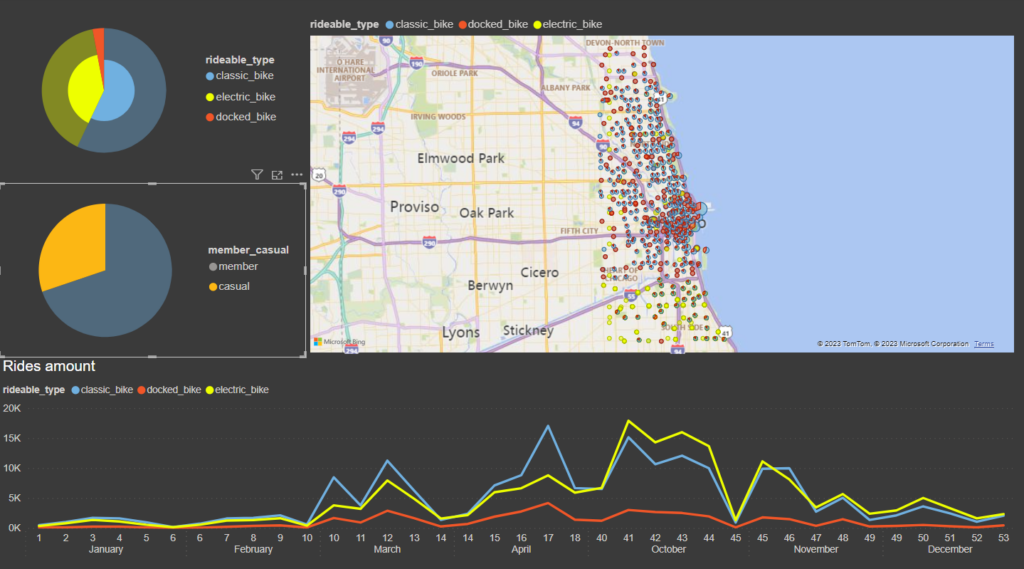
Effettivamente vediamo che i noleggi “casual” si concentrano durante l’ estate, ma piccole quantità sono presenti anche d’ inverno.
Interessante che la totalità o quasi dei noleggi di docked bike sono fatti da utenti “casual”. Bisognerebbe indagare maggiormente per capire se c’è qualche nesso tra queste due variabili.