Analisi Univariata delle variabili
In questa sezione, andremo ad esplorare, una ad una, ognuna delle variabili presenti nei nostri dataset. Può sembrare un lavoro lungo e noioso ( e forse lo è 🤓) ma è di cruciale importanza. Tramite quest’attività andremo più in intimità con i nostri dati, scoprendo cose che altrimenti avremmo ignorato.
Dati_prezzi – idImpianto
Come detto nella sezione precedente, questo dovrebbe essere il numero usato per identificare ciascun distributore. Quindi non dovrebbero esserci valori duplicati, giusto? Scopriamolo
Codice
print("tipologia variabile: " + str(type(dati_prezzi["idImpianto"][0])))
print("valori null: " + str(sum(dati_prezzi["idImpianto"].isnull())))
print("valori na: " + str(sum(dati_prezzi["idImpianto"].isna())))
print("valori duplicati: " + str(sum(dati_prezzi["idImpianto"].duplicated())))
print("valore minimo: " + str(min(dati_prezzi["idImpianto"])))
print("valore massimo: " + str(max(dati_prezzi["idImpianto"])))
Output:
tipologia variabile: <class 'numpy.int64'>
valori null: 0
valori na: 0
valori duplicati: 70171
valore minimo: 3464
valore massimo: 55039
Invece di valori duplicati ce ne sono e anche molti. Questo perchè ogni riga è un prezzo di un carburante inviato all’ente e ci sono più carburanti per ciascun distributore. Poi ogni distributore potrebbe aver inviato i propri dati più di una volta in questo dataset
In quanto valore chiave, non ci curiamo dei valori massimi e minimi, dato che numeri molto alti o molto bassi sarebbero comunque plausibili
Dati_prezzi – IsSelf
Abbiamo già visto molto di questa variabile quando abbiamo effetuato i controlli a livello dataset (prima parte dell’analisi https://www.davidemarcon.com/eda-in-python-parte-1/ ). Si tratta infatti di un Boolean che assume solo valori True e False. Abbiamo anche già visto numericamente la distribuzione della variabile, ma visto che siamo stacanovisti la guardiamo anche con un grafico
Codice per il grafico
import matplotlib.pyplot as plt
dati_prezzi["isSelf"].value_counts().plot(kind='bar', title='IsSelf')
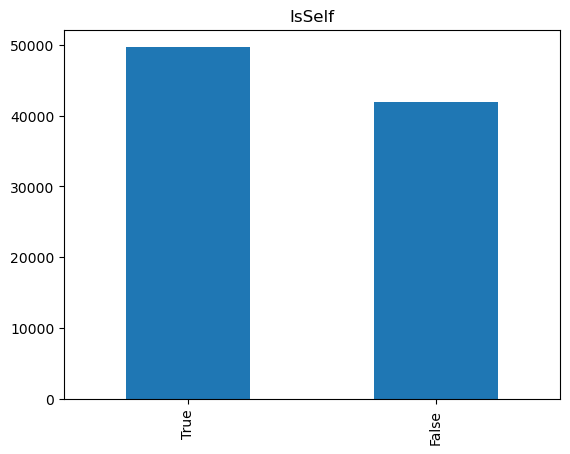
Dati_prezzi – descCarburante
In questo caso abbiamo una variabile categoriale. Sappiano già che non ci sono valori null dato il controllo che abbiamo fatto sul dataset. Vediamo quali sono i valori che questa variabile assume. Utilizziamo l’oggetto Counter per farlo.
Codice
print("ci sono "+str(len(Counter(dati_prezzi["descCarburante"]).most_common()))+" valori diversi")
Counter(dati_prezzi["descCarburante"]).most_common()
Output:
`ci sono 39 valori diversi`
`[('Benzina', 33937),
('Gasolio', 33823),
('Blue Diesel', 6067),
('GPL', 4481),
('Blue Super', 2900),
('Hi-Q Diesel', 2021),
('Metano', 1472),
('Supreme Diesel', 1396),
('HiQ Perform+', 1045),
('Gasolio Premium', 989),
('Gasolio speciale', 807),
('Benzina speciale', 367),
('Excellium Diesel', 317),
('Benzina WR 100', 303),
('Gasolio artico', 226),
('Gasolio Alpino', 166),
('DieselMax', 155),
('GNL', 139),
('Gasolio Oro Diesel', 133),
('L-GNC', 102),
('Gasolio Ecoplus', 89),
('S-Diesel', 88),
('Blu Diesel Alpino', 77),
('GP DIESEL', 71),
('Diesel Shell V Power', 62),
('Benzina Plus 98', 59),
('E-DIESEL', 49),
('Gasolio Gelo', 48),
('Gasolio Artico', 48),
('F101', 47),
('Excellium diesel', 19),
('Gasolio Energy D', 15),
('V-Power', 14),
('Diesel e+10', 7),
('Benzina Energy 98 ottani', 6),
('Benzina 100 ottani', 6),
('Benzina Shell V Power', 4),
('V-Power Diesel', 2),
('SSP98', 1)]`
In questo caso abbiamo 39 valori diversi in questa colonna, perciò un grafico non sarebbe bello da vedere visto l’elevato numero di barre che avrebbe. Accontentiamoci della lista.
Sono presenti però dei duplicati. Infatti valori diversi della colonna “descCarburante” si riferiscono molto probabilmente allo stesso carburante. Ad esempio:
- ‘V-Power Diesel’ e ‘Diesel Shell V Power’
- ‘Gasolio Gelo’,’Gasolio Artico’ e ‘Gasolio artico’
Per essere più sicuri che la sostituzione abbia senso, controlliamo che questi carburanti facciano riferimento alla stessa fascia di prezzo. Per fare ciò utilizziamo i boxplot.
Codice per il grafico
x1 = dati_prezzi[dati_prezzi["descCarburante"]=="V-Power Diesel"]["prezzo"]
x2 = dati_prezzi[dati_prezzi["descCarburante"]=="Diesel Shell V Power"]["prezzo"]
plt.boxplot ([x1, x2])
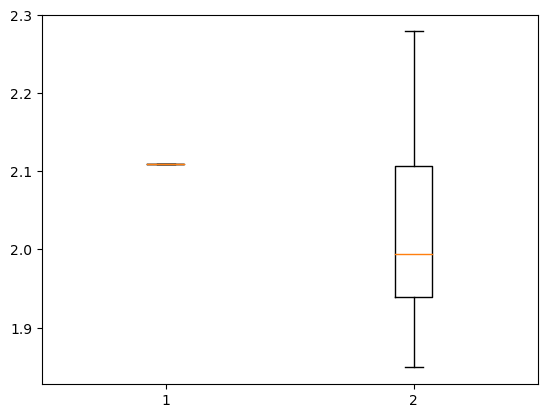
Sebbene ci siano pochissimi valori per “V-Power Diesel”, possiamo però vedere che come range di prezzi non si discosti molto da quello di “Diesel Shell V Power” (se il primo costasse 0,9€ e il secondo 2€, mi farei qualche domanda in più). Possiamo quindi uniformare queste descrizioni.
Codice
dati_prezzi.loc[dati_prezzi["descCarburante"] == "V-Power Diesel", "descCarburante"] = "Diesel Shell V Power"
Vediamo ora i box plot anche per gli altri valori.
Codice per il grafico
x1 = dati_prezzi[dati_prezzi["descCarburante"]=="Gasolio Gelo"]["prezzo"]
x2 = dati_prezzi[dati_prezzi["descCarburante"]=="Gasolio Artico"]["prezzo"]
x3 = dati_prezzi[dati_prezzi["descCarburante"]=="Gasolio artico"]["prezzo"]
plt.boxplot ([x1, x2, x3])
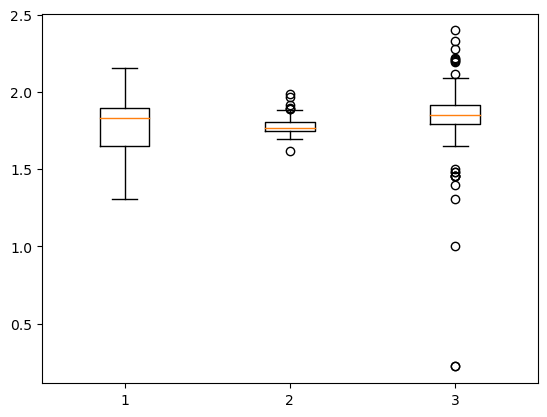
Anche in questo caso i 3 tipi di carburante fanno riferimento allo stesso range di prezzi, anche se “Gasolio artico” ha molti più outliers. Interessante il valore minimo per “Gasolio artico”. Se esistesse un distributore che veramente vende questo carburante ad un prezzo del genere, smetterei di scrivere su questo blog e inizierei un business di rivendita di gasolio artico 😂 Vediamo precisamente di che prezzo stiamo parlando.
Codice
min(dati_prezzi[dati_prezzi["descCarburante"]=="Gasolio artico"]["prezzo"])
Output:
0.222
22 centesimi a litro… Non penso sia plausibile come prezzo.
Uniformiamo intanto le descrizioni di questi tre carburanti. In seguito scremeremo anche i valori non plausibili per la colonna “prezzo”.
Codice
dati_prezzi.loc[dati_prezzi["descCarburante"] == "Gasolio Gelo", "descCarburante"] = "Gasolio Artico"
dati_prezzi.loc[dati_prezzi["descCarburante"] == "Gasolio artico", "descCarburante"] = "Gasolio Artico"
Dati_prezzi – dtComu
In questa variabile sono salvati data e orario in cui è stato comunicato quello specifico prezzo al Ministero per lo Sviluppo Economico. Vediamo la distribuzione delle date
Codice per il grafico
dati_prezzi["dtComu"].groupby([dati_prezzi["dtComu"].dt.year, dati_prezzi["dtComu"].dt.month]).count().plot(kind="bar")
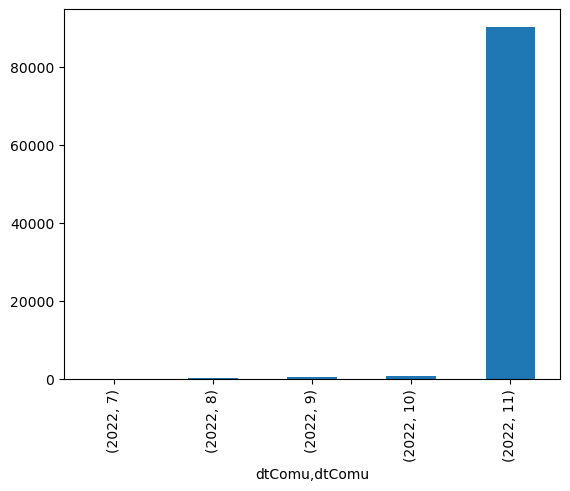
Moltissime date appartengono a Novembre 2022 (mese in cui sono stati scaricati i dati) ma ci sono ancora dei piccoli residui dei mesi precedenti.
Eliminare o non eliminare i dati? Questo è il dilemma. Effettivamente i dati dei mesi precedenti non sono molti, quindi la loro perdita non sarebbe molto grave. Mi aspetto però che i prezzi dei carburanti siano variati di poco in soli 5 mesi dato che, nel periodo di analisi, non ci sono stati particolari eventi che hanno causato scossoni nel mercato dei carburanti (se state pensando alle guerra in Ucraina, il conseguente aumento dei prezzi era già accaduto)
Controlliamo se è vero.
Codice per il grafico
x1 = dati_prezzi[dati_prezzi["dtComu"].dt.month==7]["prezzo"]
x2 = dati_prezzi[dati_prezzi["dtComu"].dt.month==8]["prezzo"]
x3 = dati_prezzi[dati_prezzi["dtComu"].dt.month==9]["prezzo"]
x4 = dati_prezzi[dati_prezzi["dtComu"].dt.month==10]["prezzo"]
x5 = dati_prezzi[dati_prezzi["dtComu"].dt.month==11]["prezzo"]
plt.boxplot ([x1, x2, x3, x4, x5])
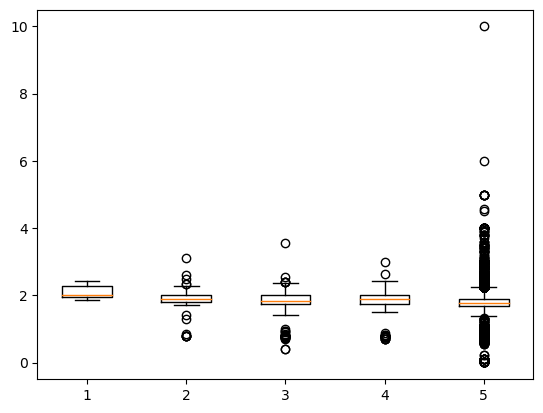
Sono molto simili tra loro. Possiamo quindi mantenere il dataset così, senza eliminare alcun dato. Essendoci poca o per nulla differenza tra i periodi, eventuali algoritmi basati su questi dati non sarebbero danneggiati dalla presenza di dati relativi a mesi precedenti
Dati_prezzi – prezzo
In questa variabile abbiamo tutti i prezzi comunicati al ministero dai distributori per i vari tipi di carburante. Mi aspetto che i valori abbiano un minimo di circa 0.4 ed un massimo di 3 (non ho mai visto un carburante costare 3/L, ma mi immagino che che un diesel/benzina artico venduto in cima ad una montagna sperduta sia abbastanza costoso 😅)
Vediamo innanzitutto alcune metriche base di questa variabile, tra cui il minimo e il massimo.
Codice
print("tipologia variabile: " + str(type(dati_prezzi["prezzo"][0])))
print("valori null: " + str(sum(dati_prezzi["prezzo"].isnull())))
print("valori na: " + str(sum(dati_prezzi["prezzo"].isna())))
print("valori duplicati: " + str(sum(dati_prezzi["prezzo"].duplicated())))a
print("valore minimo: " + str(min(dati_prezzi["prezzo"])))
print("valore massimo: " + str(max(dati_prezzi["prezzo"])))
Output:
tipologia variabile: <class 'numpy.float64'>
valori null: 0
valori na: 0
valori duplicati: 90270
valore minimo: 0.001
valore massimo: 9.999
Vediamo con l’aiuto di un grafico come si distribuiscono i valori:
Codice per il grafico
plt.hist(dati_prezzi["prezzo"], bins=100)
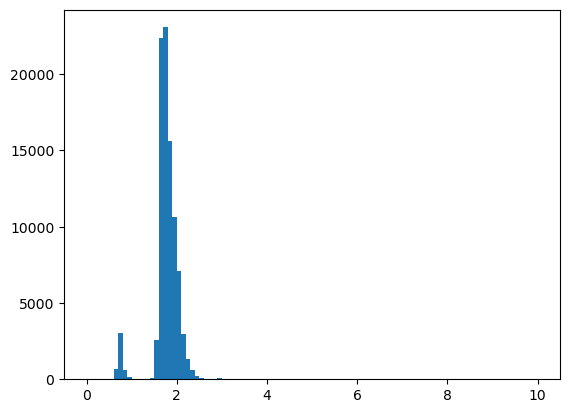
I dati sono relativi a due fasce di prezzo. 1,5-2,5 mi aspetto sia il range di benzina/diesel, mentre 0,6-0,9 mi aspetto che sia il range del GPL e simili
Essendo di fatto 2 prodotti differenti, andiamo a dividere il nostro dataset in due gruppi e a visualizzarne i dati.
Codice
dati_prezzi_min_1_25 = dati_prezzi.loc[dati_prezzi["prezzo"]<1.25]
dati_prezzi_1_25_x_3 = dati_prezzi.loc[(dati_prezzi["prezzo"]>=1.25) & (dati_prezzi["prezzo"]<3)]
Analisi primo subframe valori < 1,25
Andiamo ora a vedere i valori del primo subframe.
Codice per il grafico
plt.hist(dati_prezzi_min_1_25["prezzo"], bins=100)
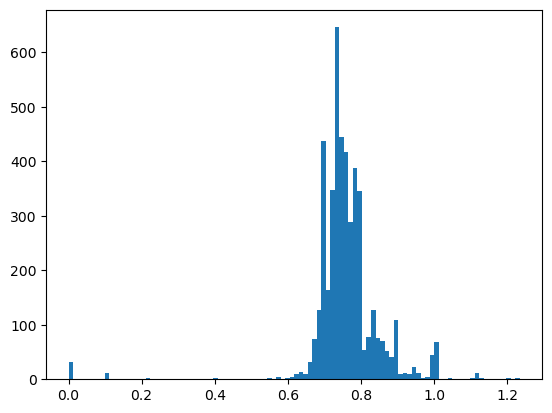
Codice
Counter(dati_prezzi_min_1_25["descCarburante"]).most_common()
[('GPL', 4481),
('Blue Super', 42),
('Metano', 19),
('Blue Diesel', 11),
('Gasolio', 10),
('Gasolio Oro Diesel', 10),
('Excellium Diesel', 8),
('Supreme Diesel', 7),
('Benzina Plus 98', 7),
('Hi-Q Diesel', 6),
('Gasolio Premium', 5),
('Gasolio Artico', 3),
('HiQ Perform+', 3),
('Benzina', 2),
('GNL', 2),
('V-Power', 2),
('Excellium diesel', 2),
('Gasolio Alpino', 2)]
Codice per il grafico
dictplot_dati_prezzi_min_1_25 = plt.boxplot(dati_prezzi_min_1_25["prezzo"])
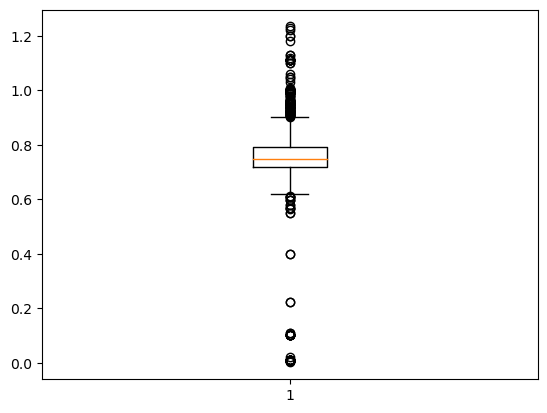
Decisamente la fascia di prezzo del GPL.
Notiamo come in questo caso ho “assegnato” il boxplot creato ad una variabile. Cosa significa? Significa che, ogni volta che creiamo un boxplot, possiamo salvarci alcune variabili che lo definiscono. In questo caso sono interessato ai valori di minimo e di massimo dei baffi. Queste variabili vengono salvate in un “dizionario” (per maggiori info su cosa sia un dizionario in Python, vai qui https://www.w3schools.com/python/python_dictionaries.asp).
Con la prossima riga di codice entriamo nel dizionario e ci andiamo a prendere il valore minimo del baffo (cioè il valore del 25° percentile).
Codice
lower_whisker = [item.get_ydata() for item in dictplot_dati_prezzi_min_1_25['caps']][0][0]
lower_whisker
Output:
0.618
Diamo una veloce occhiata agli ourliers inferiori. In questo caso andiamo a controllare l’intera tabella che Python ci restituisce in qanto vogliamo controllare quali siano i prezzi più strani e a che carburante appartengono
Codice
dati_prezzi_min_1_25.loc[dati_prezzi_min_1_25["prezzo"]<lower_whisker]
Output:
| idImpianto | descCarburante | prezzo | isSelf | dtComu | |
|---|---|---|---|---|---|
| 55 | 38150 | GPL | 0.599 | False | 2022-11-25 13:03:55 |
| 95 | 32490 | GPL | 0.549 | False | 2022-11-21 00:35:54 |
| 118 | 51335 | Metano | 0.001 | False | 2022-11-26 07:32:11 |
| 180 | 25041 | Gasolio Artico | 0.222 | True | 2022-11-23 08:16:56 |
| 181 | 25041 | Gasolio Artico | 0.222 | False | 2022-11-23 08:16:56 |
| 1203 | 26677 | Gasolio | 0.4 | True | 2022-09-17 18:53:34 |
| 1204 | 26677 | Gasolio | 0.4 | False | 2022-09-17 18:53:34 |
| 4013 | 43367 | Metano | 0.01 | False | 2022-11-15 11:41:36 |
| 7006 | 48816 | Supreme Diesel | 0.01 | True | 2022-11-19 18:48:53 |
| 11274 | 44593 | Supreme Diesel | 0.01 | True | 2022-11-21 07:30:02 |
| 11275 | 44593 | Supreme Diesel | 0.01 | False | 2022-11-21 07:30:02 |
| 11299 | 21229 | Metano | 0.01 | False | 2022-11-21 07:30:30 |
| 11411 | 47731 | Benzina Plus 98 | 0.01 | True | 2022-11-21 07:44:26 |
| 11412 | 47731 | Benzina Plus 98 | 0.01 | False | 2022-11-21 07:44:26 |
| 13706 | 52762 | GPL | 0.599 | False | 2022-11-21 12:13:03 |
| 17002 | 8627 | Hi-Q Diesel | 0.01 | True | 2022-11-22 07:12:38 |
| 17003 | 8627 | Hi-Q Diesel | 0.01 | False | 2022-11-22 07:12:38 |
| 17925 | 7554 | Supreme Diesel | 0.005 | True | 2022-11-22 08:35:08 |
| 17926 | 7554 | Supreme Diesel | 0.005 | False | 2022-11-22 08:35:08 |
| 19149 | 50199 | Metano | 0.01 | False | 2022-11-22 10:33:26 |
| 25359 | 12517 | Metano | 0.01 | False | 2022-11-23 09:45:01 |
| 25971 | 48707 | Metano | 0.01 | False | 2022-11-23 10:25:35 |
| 26395 | 11290 | Hi-Q Diesel | 0.01 | True | 2022-11-23 11:02:43 |
| 26396 | 11290 | Hi-Q Diesel | 0.01 | False | 2022-11-23 11:02:43 |
| 28646 | 35366 | Blue Super | 0.1 | False | 2022-11-23 16:34:21 |
| 28761 | 9649 | Blue Super | 0.1 | True | 2022-11-23 16:50:06 |
| 28762 | 9649 | Blue Super | 0.1 | False | 2022-11-23 16:50:06 |
| 30644 | 20195 | Blue Diesel | 0.1 | True | 2022-11-23 23:05:04 |
| 30645 | 20195 | Blue Diesel | 0.1 | False | 2022-11-23 23:05:04 |
| 34623 | 45657 | GPL | 0.569 | False | 2022-11-24 09:03:36 |
| 35445 | 54791 | Metano | 0.005 | False | 2022-11-24 09:32:06 |
| 35760 | 15513 | Excellium Diesel | 0.1 | True | 2022-11-24 09:50:03 |
| 35761 | 15513 | Excellium Diesel | 0.1 | False | 2022-11-24 09:50:03 |
| 36892 | 8387 | Benzina Plus 98 | 0.01 | True | 2022-11-24 10:53:13 |
| 36893 | 8387 | Gasolio Oro Diesel | 0.01 | True | 2022-11-24 10:53:13 |
| 37111 | 28234 | Benzina Plus 98 | 0.006 | True | 2022-11-24 11:08:36 |
| 37112 | 28234 | Benzina Plus 98 | 0.006 | False | 2022-11-24 11:08:36 |
| 37306 | 4252 | Metano | 0.01 | False | 2022-11-24 11:22:41 |
| 37531 | 46639 | GPL | 0.569 | False | 2022-11-24 11:38:07 |
| 42075 | 48065 | GPL | 0.61 | False | 2022-11-24 18:02:25 |
| 42112 | 41437 | GPL | 0.61 | False | 2022-11-24 18:04:09 |
| 42123 | 41522 | GPL | 0.61 | False | 2022-11-24 18:04:28 |
| 47765 | 43853 | Metano | 0.01 | False | 2022-11-25 06:50:38 |
| 53511 | 36113 | GPL | 0.565 | False | 2022-11-25 08:30:17 |
| 59501 | 24958 | Metano | 0.01 | False | 2022-11-25 10:15:33 |
| 60953 | 52278 | Metano | 0.01 | False | 2022-11-25 10:55:12 |
| 60954 | 52278 | GPL | 0.01 | False | 2022-11-25 10:55:12 |
| 70422 | 42710 | GNL | 0.01 | False | 2022-11-25 15:33:14 |
| 72621 | 46709 | Excellium Diesel | 0.111 | True | 2022-11-25 16:39:43 |
| 72622 | 46709 | Excellium Diesel | 0.111 | False | 2022-11-25 16:39:43 |
| 73878 | 51238 | GPL | 0.549 | False | 2022-11-25 17:17:55 |
| 74167 | 54816 | GPL | 0.609 | False | 2022-11-25 17:29:10 |
| 75917 | 54819 | GPL | 0.579 | False | 2022-11-25 17:58:41 |
| 76275 | 23392 | Blue Super | 0.1 | True | 2022-11-25 18:06:55 |
| 76276 | 23392 | Blue Super | 0.1 | False | 2022-11-25 18:06:55 |
| 76428 | 22687 | GPL | 0.611 | False | 2022-11-25 18:10:53 |
| 76702 | 54818 | GPL | 0.579 | False | 2022-11-25 18:21:50 |
| 77451 | 4432 | Metano | 0.02 | False | 2022-11-25 18:48:20 |
| 77603 | 50686 | GPL | 0.599 | False | 2022-11-25 18:55:08 |
| 82378 | 21666 | GPL | 0.569 | False | 2022-11-26 00:24:05 |
| 86036 | 8259 | Gasolio | 0.005 | True | 2022-11-26 06:55:39 |
| 86037 | 8259 | Gasolio | 0.005 | False | 2022-11-26 06:55:39 |
| 86040 | 8259 | Blue Diesel | 0.005 | True | 2022-11-26 06:55:39 |
| 86041 | 8259 | Blue Diesel | 0.005 | False | 2022-11-26 06:55:39 |
Come valore minimo credibile possiamo tenere 0.450€. Ho scelto questo numero basandomi sulla mia esperienza personale e con una veloce ricerca in internet sui prezzi dei combustibili
Analisi secondo subframe 1,25 < valori < 3
Codice per il grafico
plt.hist(dati_prezzi_1_25_x_3["prezzo"], bins=100)
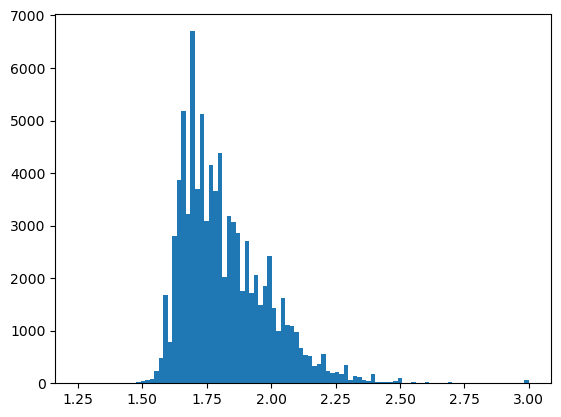
Codice per il grafico
dictplot_dati_prezzi_1_25_x_3 = plt.boxplot(dati_prezzi_1_25_x_3["prezzo"])
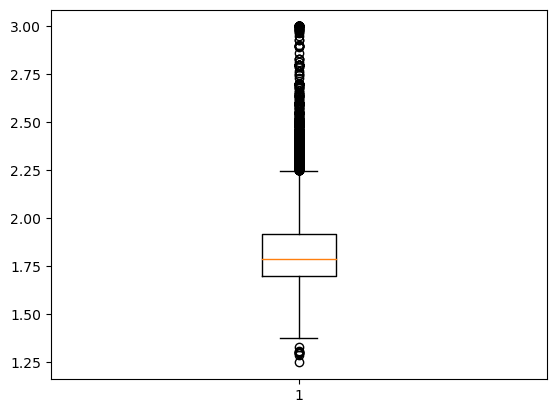
Qui possiamo vedere come i prezzi siano fortemente concentrati poco al di sotto dei 2€/litro. Ci sono però anche diversi outliers superiori. Andiamoli a scoprire:
Codice
upper_whisker2 = [item.get_ydata() for item in dictplot_dati_prezzi_1_25_x_3['caps']][1][0]
In questo caso andiamo ad utilizzare il “Counter most common” perchè vogliamo controllare quali siano i carburanti presenti in questi outliers. Di fatto un tetto massimo di 3€/L può anche essere credibile, ma dipende da che tipo di carburante è presente.
Codice
Counter(dati_prezzi_1_25_x_3[dati_prezzi_1_25_x_3["prezzo"]>upper_whisker2]["descCarburante"]).most_common()
Output:
[('Hi-Q Diesel', 443),
('Metano', 367),
('Gasolio', 266),
('HiQ Perform+', 97),
('Gasolio Premium', 87),
('GNL', 86),
('Benzina', 76),
('Supreme Diesel', 68),
('Blue Diesel', 42),
('Blue Super', 36),
('L-GNC', 25),
('Gasolio speciale', 19),
('Benzina speciale', 18),
('Gasolio Ecoplus', 9),
('Benzina WR 100', 8),
('Gasolio Oro Diesel', 5),
('Excellium Diesel', 3),
('Gasolio Artico', 3),
('Benzina Plus 98', 2),
('E-DIESEL', 1),
('V-Power', 1),
('Diesel Shell V Power', 1)]
Ci sono diverse varietà di carburanti costosi, però anche “benzina”, “gasolio” o “metano” che generalmente non hanno prezzi così elevati. Continuo quindi l’analisi mantenendo anche questi outliers superiori, ricordandomi però di questa scelta.
Creiamo finalmente il nostro dataframe finale di dati_prezzi, con al suo interno solamente i dati relativi ai prezzi che riteniamo credibili.
Codice
dati_prezzi_cl = dati_prezzi.loc[(dati_prezzi["prezzo"]>=0.45) & (dati_prezzi["prezzo"]<3)]
Guardiamone i dati principali.
Codice
dati_prezzi_cl.info()
Output:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 91408 entries, 0 to 91557
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 idImpianto 91408 non-null int64
1 descCarburante 91408 non-null object
2 prezzo 91408 non-null float64
3 isSelf 91408 non-null bool
4 dtComu 91408 non-null datetime64[ns]
dtypes: bool(1), datetime64[ns](1), float64(1), int64(1), object(1)
memory usage: 3.6+ MB
C’è solo una piccola cosa ancora da sistemare. Dall’output della riga precedente notiamo come ci siano 91408 righe, ma che l’indice della tabella vari dallo 0 al 91557. Questo significa che in qualche punto della tabella l’indice salta qualche numero. Andiamo subito a correggerlo.
Codice
dati_prezzi_cl = dati_prezzi_cl.reset_index()
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 91408 entries, 0 to 91407
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 index 91408 non-null int64
1 idImpianto 91408 non-null int64
2 descCarburante 91408 non-null object
3 prezzo 91408 non-null float64
4 isSelf 91408 non-null bool
5 dtComu 91408 non-null datetime64[ns]
dtypes: bool(1), datetime64[ns](1), float64(1), int64(2), object(1)
memory usage: 3.6+ MB
Dati_anagrafica – idImpianto
Anche in questo caso abbiamo gli identificatori di ogni distributore. Anzi, è proprio grazie a questo dataset che possiamo identificare ogni singolo distributore. Qui infatti i valori di IdImpianto devono essere delle chiavi uniche, non possono esserci duplicati in questa colonna. Andiamo subito a vedere se è così.
Codice
print("numero di valori duplicati: "+str(sum(dati_anagrafica_cl["idImpianto"].duplicated())))
Output:
numero di valori duplicati: 0
Dati_anagrafica – Gestore
Anche in questo caso utilizziamo l’oggetto Counter per contare le occorrenze di ogni singola categoria presente in questa colonna.
Codice
print("ci sono "+str(len(Counter(dati_anagrafica_cl["Gestore"]).most_common()))+" valori diversi")
Counter(dati_anagrafica_cl["Gestore"]).most_common()
Output:
`ci sono 13620 valori diversi`
`[('SERVIZI & GESTIONI ITALIA S.R.L.', 941),
('IP SERVICES S.R.L.', 797),
('T.D.M. S.R.L.', 511),
('SERVIZI & GESTIONI ITALIA srl', 373),
('SERVIZI E GESTIONI ZENIT S.R.L. IN SIGLA - ZENIT S.R.L.', 225),
('ENI FUEL S.P.A.', 221),
('IP', 160),
('GESTIONI INNOVATIVE ITALIA S.R.L.', 140),
............
('MG FUEL MANAGEMENT S.R.L.', 2),
('CURTI CHRISTIAN', 2),
("ROMA CARBURANTI SOCIETA' A RESPONSABILITA' LIMITATA SEMPLIFICATA", 2),
('SHAIK MAHABUB ALOM', 2),
('SHEIKH AL AMIN', 2),
('DELLA BINA SANTE E PIAZZA FIORELLA - SOCIETA IN NOME COLLETTIVO', 2),
("PETROLI 2000 SOCIETA' A RESPONSABILITA' LIMITATA SEMPLIFICATA", 2),
('ROMANIELLO DOMENICO', 2),
('FLAMINIA CARBURANTI SNC', 2),
('GE.MA. - S.N.C. DI MARFIA CLAUDIO ANTONIO E DI BELLO MATTEO', 2),
('GEDOIL SRL', 2),
('NF OIL S.N.C. DI CAVOLA FABRIZIO', 2),
('COLOMBO OIL SAS DI MATTEI VENANZO E PASSARIELLO GIANLUCA', 2),
('VERDE CAMPI DI VERDE VALENTINA', 2),
('MATTEI MARIA CRISTINA', 2),
('GESTIONE ITALIA S.A.S. DI EGIDI BRUNO', 2),
('MARINI SERVIZI S.R.L.', 2),
('luca.ferretti', 2),
('MA.LU SAS', 2),
('3S PETROL SERVICE S.R.L.', 2),
("CAMA PETROLI DI MAZZONE STEFANO & C. - SOCIETA' IN ACCOMANDITA SE MPLICE",
2),
('RE.SI. CARBURANTI SAS DI SASIVARI FLJORIM', 2),
('F.G.I. SAS DI NUZZO GIULIANA & C.', 2),
('UBERTINI GIUSEPPE', 2),
...]`
In questo caso non ci è possibile agglomerare diversi valori. come abbiamo fatto per dati_prezzi – desCarburante in quanto c’è troppo variabilità. Anche se a colpo d’occhio riusciamo a vedere qualche valore anomalo (esempio: SERVIZI & GESTIONI ITALIA S.R.L. e SERVIZI & GESTIONI ITALIA srl), in questo caso è preferibile passare oltre. Se necessario possiamo tornare a questo punto e addentrarci maggiormente
Dati_anagrafica – Bandiera
Anche in questo caso abbiamo una variabile categoriale. Mi aspetto che ci siano meno valori diversi rispetto a dati_anagrafica – Gestore, quindi potrebbe essere possibile anche un aggiustamento dei presenti. Prima però di stampare a video i diversi valori, dobbiamo rendere tutto il contenuto di questa colonna maiuscolo, in modo da rendere i nomi delle Bandiere più omogenei.
Codice
for i in range(0,len(dati_anagrafica_cl)):
dati_anagrafica_cl.loc[i,"Bandiera"] = dati_anagrafica_cl.loc[i,"Bandiera"].upper()
Per andare meglio a trovare i valori da sistemare, stampiamo a video i valori in ordine alfabetico.
Codice
print("ci sono "+str(len(Counter(dati_anagrafica_cl["Bandiera"]).most_common()))+" valori diversi")
sorted(Counter(dati_anagrafica_cl["Bandiera"]).most_common())
Output:
[('357', 9),
('4', 7),
('78', 1),
('7SETTE', 15),
('ACI', 8),
('ACI_CL', 4),
('ACI_PT', 3),
('ACTON1Q', 24),
('ADAMO IDROCARBURI', 14),
('AF PETROLI', 29),
('AG ENERGY', 1),
('AGIP ENI', 4036),
('ALA', 30),
('ALIFUEL', 7),
('ALOIL', 2),
('AP', 21),
('AP STAZIONI DI SERVIZIO', 9),
('API-IP', 4003),
('AQUILA', 43),
('ARGENTARIO CARBURANTI', 1),
('AUCHAN', 20),
('AVIA', 11),
('BANDIERA NON SELEZIONATA', 3),
('BARTOLUCCI', 7),
('BC', 26),
('BELTRALLO CARBURANTI', 3),
('BENECO', 11),
('BENZA', 15),
('BERTELLI CARBURANTI', 11),
('BEYFIN', 112),
('BIANCO CARBURANTI', 14),
('BIANCOPETROLI', 2),
('BIBBIENA CARBURANTI', 1),
('BIG', 1),
('BIOIL', 3),
('BLANCO PETROLI', 6),
('BLF', 2),
('BLUOIL', 1),
('BLUPARK', 1),
('BN PETROLI', 5),
('BOGONI', 9),
('BOLGAN', 1),
('BP BACHIORRINI PETROLI', 1),
('BPETROL', 15),
('CAMER', 21),
('CANCELLIERI CARBURANTI', 8),
('CANESTRELLI PETROLI', 2),
('CAPRI SOC COOP', 1),
('CARBONOIL', 1),
('CARBURANTI DISCOUNT', 6),
('CARBURANTI PAGANELLI', 1),
('CARBURANTIVECCHIETTI', 7),
('CARREFOUR', 10),
('CARRIERO ENERGY', 4),
('CARSIE', 1),
('CASAREALE', 2),
('CATRIA ENERGY', 5),
('CENTRALE METANO FOLIGNO', 5),
('CLER CARBURANTI', 1),
('COIL', 23),
('COLAGROSSI CARBURANTI', 1),
('CONAD', 45),
('COOP', 3),
('COSTA CARBURANTI', 2),
('COSTANTIN', 105),
('CP', 5),
('CRISTOFORETTI', 4),
('CUCAGAS', 3),
('CURRERI CARBURANTI', 1),
('D AMICO', 1),
('DALL AGLIO', 3),
('DALLE PETROLI', 3),
('DBCARBURANTI', 30),
('DE ANGELIS CARBURANTI', 1),
('DELTA', 3),
('DELTA ENERGY', 6),
('DIGISERVICE', 2),
('DIL', 1),
('DILL S', 25),
('DIS-CAR', 30),
('DP CARBURANTI', 1),
('DV OIL', 1),
('E-SMART', 2),
('ECO FUEL', 6),
('ECOIL', 1),
('ECONOMY', 9),
('ECONOMYSRL', 15),
('EDISON METANO', 9),
('EDRA OIL', 20),
('EGO', 94),
('EIS STATION', 1),
('EKOENERGY', 1),
('EKOMOBIL', 2),
('EMME PETROLI', 1),
('ENERCOOP', 31),
('ENERFUEL', 2),
('ENERGAS', 62),
('ENERGIA FLUIDA', 3),
('ENERGY RETE', 6),
('ENERGY STATION', 1),
('ENERGYCA', 20),
('ENERPETROLI', 68),
('ENJOIL', 2),
('EOS', 40),
('ERNESTO RONDINI', 9),
('ESSE OIL', 1),
('ESSEPI', 1),
('ESSO', 2205),
('EUGAS', 3),
('EUROCAP PETROLI', 4),
('EUROPAM', 202),
('EUROPETROL', 5),
('EUROPETROLI', 1),
('EUROSELF', 1),
('FAST FUEL GROUP', 22),
('FELTREGAS', 1),
('FGS', 9),
('FIAMMA 2000', 18),
('FIORESE BERNARDINO', 2),
('FIRMIN', 10),
('FM ENERGY', 2),
('FRANZON SNC', 1),
('FRATELLI GENNARO', 1),
('FSTATION', 6),
('FUEL99', 1),
('FUELPP', 2),
('FULGOROIL', 10),
('GAFFOIL', 7),
('GALOIL CARBURANTI', 4),
('GAMMA PETROLI', 5),
('GAN', 10),
('GARAGE ROBERTO', 1),
('GAS E', 6),
('GASAUTO', 8),
('GATTI CARBURANTI', 2),
('GATTO CARBURANTI', 1),
('GEP CARBURANTI', 11),
('GGENERGY', 1),
('GIAP', 132),
('GNP', 36),
('GO', 17),
('GRAZI PETROLI', 4),
('GREENFUELCOMPANY', 3),
('GREGOIL', 1),
('HERMES', 1),
('IBLEA PETROLI', 16),
('ICM', 35),
('IES', 16),
('INTERPETROL', 7),
('IPER STATION', 11),
('ITALA PETROLI', 25),
('ITALIA CARBURANTI', 4),
('ITALIANA CARBURANTI', 15),
('KELDER', 1),
('KEROPETROL', 125),
('KEROTRIS', 32),
('KOSTNER', 10),
('LANDINI E VIGNETTI', 1),
('LFC PETROLI', 6),
('LORO', 68),
('LP CARBURANTI', 7),
('LUKOIL', 44),
('MACMARCHETTICARBURANTI', 9),
('MADOGAS NATURAL ENERGY', 2),
('MAJOR', 21),
('MAREMMANA PETROLI', 1),
('MC PETROLI', 2),
('MEN8', 1),
('MENGA PETROLI', 29),
('MESSINA CARBURANTI', 1),
('MESU E RIOS', 2),
('METANAUTO GROUP', 6),
('METANO SPILAMBERTO', 1),
('MF CARBURANTI', 2),
('MORO', 8),
('MOVE 2', 1),
('MOVEO', 2),
('MYOIL', 10),
('NATURAL GAS', 12),
('NETFUEL', 1),
('NEW ENERGY', 2),
('NOALOIL', 22),
('NOBILE OIL', 29),
('NONNAISA STATION', 3),
('OIL DISCOUNT', 2),
('OIL ITALIA', 51),
('OIL ONE', 15),
('OLL', 1),
('ON CARBURANTI', 1),
('OROIL', 3),
('OUTLETCARBURANTI', 2),
('P F M', 1),
('PAD', 2),
('PAM OIL', 1),
('PAN OIL', 1),
('PERIN', 5),
('PETROL COMPANY', 31),
('PETROL FUEL', 1),
('PETROL GAMMA', 53),
('PETROLNAFTA', 3),
('PETROLPICENA', 10),
('PICCINI FUELS', 13),
('PIEROPAN ELISA', 1),
('PINGUINO CARBURANTI', 1),
('PLUS', 1),
('PM', 10),
('POMPE BIANCHE', 3173),
('POWERGHOST', 1),
('PUNTO NORD', 1),
('Q8', 2697),
('RATTI', 7),
('REALE', 1),
('RENO GAS ENERGY', 7),
('REPSOL', 45),
('RESOIL', 1),
('RESTIANI', 2),
('RETITALIA', 177),
('ROSINA FUEL', 1),
('RPETROLI', 1),
('SACAT', 4),
('SACED', 8),
('SAN MARCO PETROLI', 107),
('SANROCCO CARBURANTI', 1),
('SARNI OIL', 41),
('SEP', 1),
('SEPA', 8),
('SEVENOIL', 1),
('SHELL', 46),
('SIA FUEL', 65),
('SICILPETROLI', 37),
('SIDOTI FUEL', 1),
('SILCASRL', 1),
('SIMEONE CARBURANTI', 3),
('SIMONETTI PETROLI', 23),
('SMAF', 30),
('SOCOGAS', 27),
('SOCOMCI', 1),
('SODIFA', 3),
('SODIGAS', 3),
('SOM/OMV', 1),
('SOMMESE PETROLI', 50),
('SP ENERGIA SICILIANA', 37),
('SR 203', 1),
('STOM', 2),
('TAM FULL SERVICE STATION', 2),
('TAM SERVICE', 2),
('TAMOIL', 1473),
('TAOIL', 8),
('TENERGY', 3),
('TERMOVENETA SRL', 4),
('TERNI CARBURANTI', 1),
('TOIL', 45),
('TOMA PETROLI', 3),
('TOMMASINI CARBURANTI', 2),
('TOTAL ERG', 1),
('TRECONFINICARBURANTI', 1),
('TRIVENGAS', 8),
('TTP', 15),
('TUSCIAPETROLI', 1),
('UP', 6),
('VEGA', 85),
('VERLINGAS', 1),
('VIGNETTI', 3),
('VITAL', 2),
('VULCANGAS', 4),
('XOIL', 2),
('ZANNONI', 6)]
I valori che dobbiamo sistemare sono:
- (‘AP’, 21), (‘AP Stazioni di Servizio’, 9),
- (‘Economy’, 9), (‘Economysrl’, 15),
Codice
dati_anagrafica_cl.loc[dati_anagrafica_cl["Bandiera"] == "AP Stazioni di Servizio", "Bandiera"] = "AP"
dati_anagrafica_cl.loc[dati_anagrafica_cl["Bandiera"] == "Economy", "Bandiera"] = "Economysrl"
Dati_anagrafica – Tipo Impianto
Un’altra variabile categoriale. Dato che questa colonna è relativa alle differenti tipologie di impianto, in questo caso mi aspetto una variabilità molto più bassa, ad esempio 5 valori.
Codice
print("ci sono "+str(len(Counter(dati_anagrafica_cl["Tipo Impianto"]).most_common()))+" valori diversi")
Counter(dati_anagrafica_cl["Tipo Impianto"]).most_common()
Output:
`ci sono 2 valori diversi`
`[('Stradale', 20755), ('Autostradale', 423)]`
Ci sono infatti soltando due tipologie: impianto_ stradale e autostradale. Dato che ci sono solo 2 stati di questa variabile, potrebbe di fatto diventare una variabile booleana. Come visto in precedenza con dati_prezzi – isSelf, questa variabile potrebbe diventare dati_anagrafica – isStradale. Per semplicità manteniamo questa variabile categoriale. Ipotizzo che in futuro questo dataset possa essere unito con altri dataset, dove ci siano anche più tipologie di impianto
Dati_anagrafica – Nome Impianto / Indirizzo
Anche in questo caso abbiamo variabili categoriali, ma sarebbe difficile distinguere valori corretti dai valori non corretti. Potremmo fare un controllo duplicati, in modo da cercare se lo stesso impianto è stato inserito a database 2 volte, con quindi 2 idImpianto differenti. Ritengo però che questo controllo sia meglio farlo tramite le coordinate geografiche
Dati_anagrafica – Comune
In questo caso eventuali errori potrebbero essere errori di digitazione (non so infatti se questa variaible è inserita in automatico dal sistema o se è l’utente che deve digitarla) o errori di minuscole/maiuscole
Per risolvere intanto il secondo problema, portiamo tutta la colonna in maiuscolo.
Codice
for i in range(0,len(dati_anagrafica_cl)):
dati_anagrafica_cl.loc[i,"Comune"] = dati_anagrafica_cl.loc[i,"Comune"].upper()
Vediamo ora il problema degli errori di battitura. Stampiamo anche in questo caso tutti i valori in ordine alfabetico.
Codice
print("ci sono "+str(len(Counter(dati_anagrafica_cl["Comune"]).most_common()))+" valori diversi")
sorted(Counter(dati_anagrafica_cl["Comune"]).most_common())
Output:
`ci sono 5239 valori diversi`
`[(' FRAZIONE POMONTE - VIA DEL PUGLIA SNC 06035 GUALDO CATTANEO (PG) SNC 06035 GUALDO CATTANEO',
1),
('ABANO TERME', 7),
('ABBADIA SAN SALVATORE', 2),
('ABBASANTA', 2),
('ABBIATEGRASSO', 12),
('ABETONE', 1),
('ACATE', 3),
('ACCETTURA', 1),
('ACERENZA', 1),
('ACERNO', 1),
...................
('CASPOGGIO', 1),
('CASSAGO BRIANZA', 1),
("CASSANO ALL'IONIO", 7),
("CASSANO D'ADDA", 5),
('CASSANO DELLE MURGE', 3),
('CASSANO IRPINO', 1),
('CASSANO MAGNAGO', 4),
...]`
Ci sono 5239 valori diversi, di certo non mi metto a leggerli tutti 😂 Possiamo però già vedere dal primo valore della lista che questa colonna presenta degli errori. Per individuarne di simili possiamo ricercare all’interno di questa colonna le righe che contengono numeri in cifra, parentesi tonde o trattini. Vediamo come fare con le seguenti righe di codice.
Codice
y=[]
caratteri_sospetti = ["0","1","2","3","4","5","6","7","8","9","(",")","-"]
for i in range(0,len(dati_anagrafica_cl["Comune"])):
for carattere_sospetto in caratteri_sospetti:
if carattere_sospetto in dati_anagrafica_cl["Comune"][i]:
y.append(i)
Abbiamo praticamente creato un doppio ciclo. Con il primo ciclo andiamo a scorrere tutti i valori della colonna “Comune”, mentre con il secondo ciclo andiamo a scorrere tutti i caratteri sospetti. Se un certo Comune ha al suo interno un carattere sospetto, salviamo l’indice di quella riga all’interno della variabile “y”
Andiamo infine ad eliminare tutte le righe appena selezionate e a riordinare l’indice della tabella.
Codice
dati_anagrafica_cl.drop(y, inplace=True)
dati_anagrafica_cl = dati_anagrafica_cl.reset_index()
Dati_anagrafica – Latitudine / Longitudine
Dall’analisi che abbiamo fatto a livello del dataframe sappiamo che all’interno di queste colonne sono presenti dei float, perciò sulla tipologia dei valori siamo già apposto
Vediamo ora se, controllando sia la latitudine che la longitudine, esistano valori duplicati
Codice
print("ci sono "+ str(sum(dati_anagrafica_cl[["Latitudine","Longitudine"]].duplicated()))+" valori duplicati")
Output:
ci sono 109 valori duplicati
Abbiamo infatti 109 valori duplicati. Questo significa che con le stesse coordinate geografiche abbiamo 2 o più distributori. Questo è chiaramente non possibile, andiamo quindi a modificare il nostro dataframe.
Codice
dati_anagrafica_cl.loc[:,["Latitudine","Longitudine"]].drop_duplicates(inplace=True)
Tramite la precedente riga di codice, abbiamo cercato i valori duplicati concatenando Latitudine e Longitudine. In caso Python ne trovi uno, viene conservato solamente la prima riga con quelle coordinate, mentre le altre vengono cancellate.
Abbiamo ora finito con le analisi univariate delle variabili. Possiamo passare a quelle multivariate
Analisi multivariata delle variabili
In questo paragrafo dell’analisi andiamo a mettere in relazione diverse variabili del dataset per capire se le due metriche variano assieme
isSelf vs Prezzo
In questo caso dobbiamo capire se al variare della variabile isSelf, ci sia qualche effetto sulla variabile prezzo. In quanto isSelf è una variabile booleana e ha quindi solo 2 valori, divideremo i valori dei prezzi in due gruppi e ne plotteremo i boxplot. Mi aspetto che quando la variabile isSelf è True, si abbia un decremento dei prezzi
Per fare quest’analisi utilizziamo solamente i carburanti di tipo “Benzina” e “Gasolio” dato l’elevato numero di occorrenze.
Proviamo a vedere come variano i prezzi per la benzina.
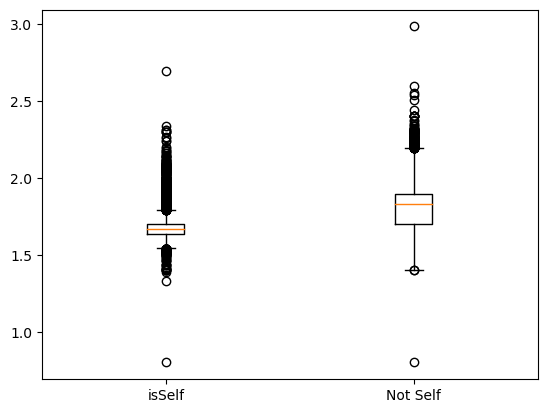
Codice per il grafico
x1 = dati_prezzi_cl[(dati_prezzi_cl["descCarburante"]=="Benzina") & (dati_prezzi_cl["isSelf"]==True)]["prezzo"]
x2 = dati_prezzi_cl[(dati_prezzi_cl["descCarburante"]=="Benzina") & (dati_prezzi_cl["isSelf"]==False)]["prezzo"]
plt.boxplot([x1, x2], labels=["isSelf","Not Self"])
Stesso grafico lo creiamo per il caso del Gasolio.
Codice per il grafico
x1 = dati_prezzi_cl[(dati_prezzi_cl["descCarburante"]=="Gasolio") & (dati_prezzi_cl["isSelf"]==True)]["prezzo"]
x2 = dati_prezzi_cl[(dati_prezzi_cl["descCarburante"]=="Gasolio") & (dati_prezzi_cl["isSelf"]==False)]["prezzo"]
plt.boxplot([x1, x2], labels=["isSelf","Not Self"])
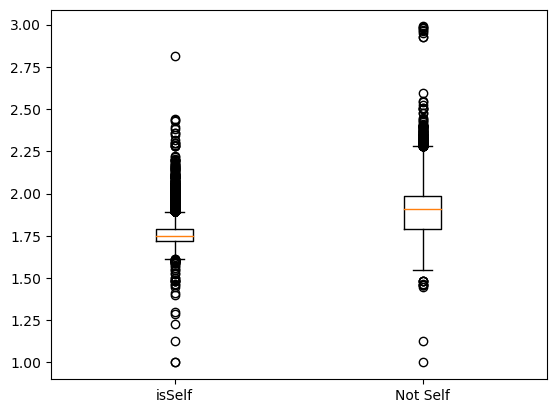
I prezzi sono di fatto più bassi quando il dato è relativo ad una pompa di benzina “Self”
Tipologia Impianto vs Prezzo
La stessa tipologia di analisi la possiamo fare tra “Tipo Impianto” e “Prezzo”. Come abbiamo visto in precedenza ci sono 2 tipologie di impianto:
- Stradale
- Autostradale
Mi immagino quindi che lo stesso carburante costi di più in un impianto austostradale rispetto ad uno stradale. Per controllare se è vero dobbiamo prima però unire i dataset con la seguente riga di codice:
Codice
dati_prezzi_anagrafica = pd.merge(dati_anagrafaica_cl,dati_prezzi_cl, on="idImpianto")
Codice per il grafico
x1 = dati_prezzi_anagrafica[(dati_prezzi_anagrafica["descCarburante"]=="Benzina") & (dati_prezzi_anagrafica["Tipo Impianto"]=="Stradale")]["prezzo"]
x2 = dati_prezzi_anagrafica[(daati_prezzi_anagrafica["descCaarburante"]=="Benzina") & (dati_prezzi_anagrafica["Tipo Impianto"]=="Autostradale")]["prezzo"]
plt.boxplot([x1, x2], labels=["Stradale","Autostradale"])
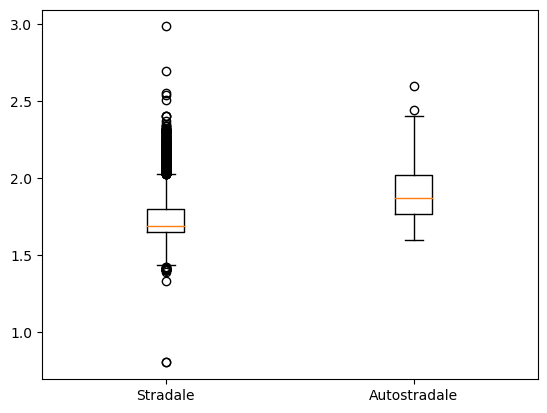
Sembra proprio che sia così. Vediamo se la situazione è la stessa anche per il Gasolio
Codice per il grafico
x1 = dati_prezzi_anagrafica[(dati_prezzi_anagrafica["descCarburante"]=="Gasolio") & (dati_prezzi_anagrafica["Tipo Impianto"]=="Stradale")]["prezzo"]
x2 = dati_prezzi_anagrafica[(dati_prezzi_anagrafica["descCarburante"]=="Gasolio") & (dati_prezzi_anagrafica["Tipo Impianto"]=="Autostradale")]["prezzo"]
plt.boxplot([x1, x2], labels=["Stradale","Autostradale"])
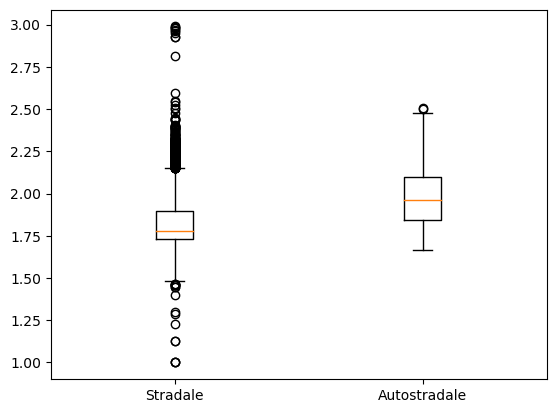
Interessante anche la differenza nel numero di outliers tra le due categorie. Come visto in precedenza, ci sono 20755 record per la tipologia “Stradale” e solamente 423 per “Autostradale”. Ciò non toglie che nel caso delle autostrade gli impianti potrebbero essere più precisi nella comunicazione dei dati al Ministero dello Sviluppo Economico
Prezzo vs Latitudine
I prezzi dei carburanti cambiano tra il nord e il sud italia? Per scoprirlo andremo a plottare i prezzi registrati di uno specifico carburante (Benzina o Gasolio) e la loro latitudine. Vista la grande quantità di dati, è bene anche impostare un certo valore di trasparenze in questi grafici, in modo da avere un’idea anche della densità dei punti.
Codice per il grafico
plt.scatter(dati_prezzi_anagrafica[dati_prezzi_anagrafica["descCarburante"] == "Benzina"]["Latitudine"],dati_prezzi_anagrafica[dati_prezzi_anagrafica["descCarburante"] == "Benzina"]["prezzo"],alpha=0.2)
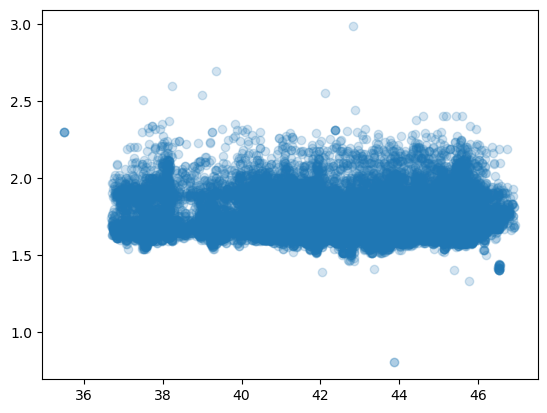
Vediamo gli stessi dati anche per il Gasolio
Codice per il grafico
plt.scatter(dati_prezzi_anagrafica[dati_prezzi_anagrafica["descCarburante"] == "Gasolio"]["Latitudine"],dati_prezzi_anagrafica[dati_prezzi_anagrafica["descCarburante"] == "Gasolio"]["prezzo"],alpha=0.2)
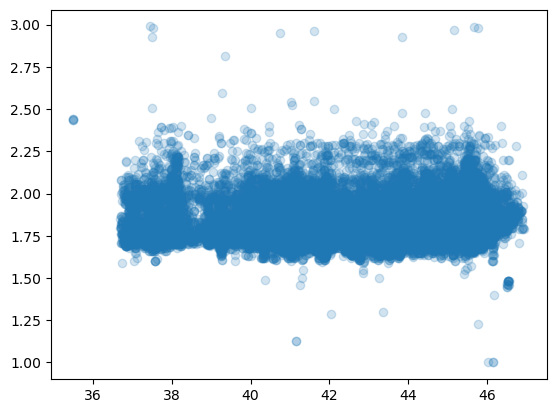
Vediamo come tendenzialmente i prezzi rimangano gli stessi e non variano in base alla latitudine. Non c’è quindi una differenza significativa tra i prezzi negli impianti del Nord Italia e del Sud Italia
Siamo arrivati alla fine di questa EDA. Spero che la lettura sia stata interessante e che possa aver dato qualche spunto di miglioramento. Se hai consigli od osservazioni, scrivi pure qui sotto nei commenti 👍