Le istituzioni come Istat ed Eurostat fanno un gran lavoro nel rilevare e catalogare i dati delle nazioni. Spaziano su moltissimi argomenti e i dati raccolti sono molto utili:
- Un’azienda può utilizzarli per conoscere meglio il mercato in cui opera o in cui vuole investire.
- Istituzioni e associazioni possono usarli per capire meglio l’entità di un problema che vogliono risolvere o capire se le azioni portate avanti in passato hanno avuto qualche effetto sul presente.
- Anche i giornalisti possono trarne vantaggio perchè, citando Deming: senza i dati sei solo un’altra persona con un’opinione.
Oltre a raccogliere e a catalogare i dati, queste organizzazioni si occupano anche di divulgazione. All’interno dei loro portali possiamo trovare blog e newsletter che permettono a normali cittadini di conoscere meglio il mondo che li circonda, di confrontare i dati con quanto riportato da altre fonti, come giornali o social, e anche di analizzare autonomamente i dati tramite qualche grafico.
Ci sono però situazioni in cui gli utilizzatori finali di questi dati hanno esigenze molto specifiche, qualcosa che la semplice interfaccia grafica di questi siti non può offrire. A volte sono necessarie analisi ad hoc, anche incrociando diversi datasets, in modo da fornire informazioni precise a persone specifiche.
Proprio con quest’idea ho deciso di creare questo nuovo articolo.
Vantaggi:
- Informazioni dettagliate per supportare decisioni di aziende, organizzazioni o investigazioni di giornalisti
Dati:
- Liberamente disponibili in Eurostat
Schema generale
L’obiettivo è quello di creare uno spazio dove le persone possano accedere a queste analisi ad hoc basate sui dati di Eurostat. In questo modo grafici e tabelle possono essere arricchite incrociando i dati da altre fonti e ripulendoli in modo adeguato.
Lo spazio che utilizzerò per presentare i dati sarà un report di PowerBI, dato che in questo modo potrò riutilizzare il collegamento con AWS già impostato in passato.
È importante che i dati siano costantemente aggiornati, in modo che chi ne usufruisce non si debba mai chiedere se sia meglio utilizzare il report in PowerBI o scaricare autonomamente i dati da Eurostat. Se così fosse, la creazione di questa dashboard perderebbe un pò di senso.
Come mantengo i dati aggiornati?
Praticamente tutto l’articolo ruota intorno a questo tema. Come faccio a tenere i dati sempre aggiornati per PowerBI?
Il primo ingranaggio del sistema è una funzione Lambda che va a confrontare le date degli ultimi aggiornamenti dei dataset che abbiamo scaricato in una cartella S3 con le date degli ultimi aggiornamenti presenti nei metadati di Eurostat. In questo caso non parliamo però di quando ho scaricato il dataset, ma di quando sono stati aggiornati i dati. Facendo un esempio: se i dati del dataset gusti_pizza_24 sono stati aggiornati l’ultima volta il 1 Agosto 2024 e io scarico i dati il 1 Settembre 2024, la data dell’ultimo aggiornamento in S3 sarà il 1 Agosto 2024.
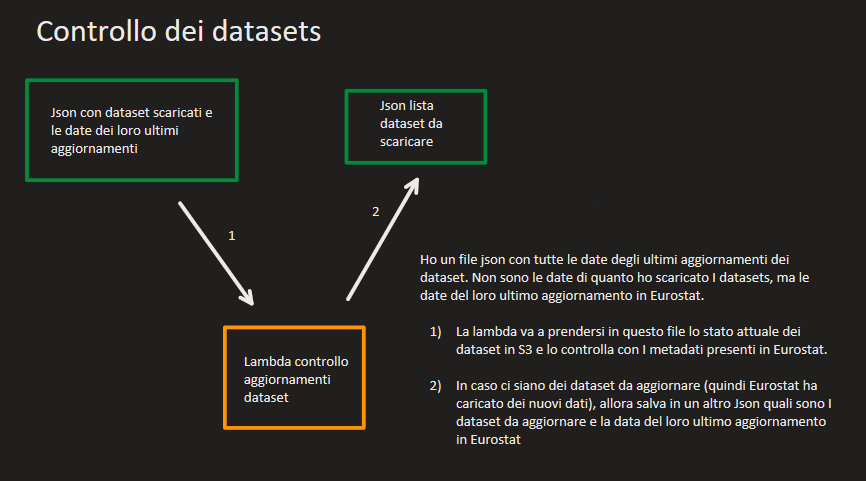
Una volta confrontate le date, mi salvo in un Json solamente i nomi dei dataset che devo aggiornare, tralasciando tutti gli altri. Questi vengono poi passati al secondo ingranaggio di questo sistema, una istanza EC2.
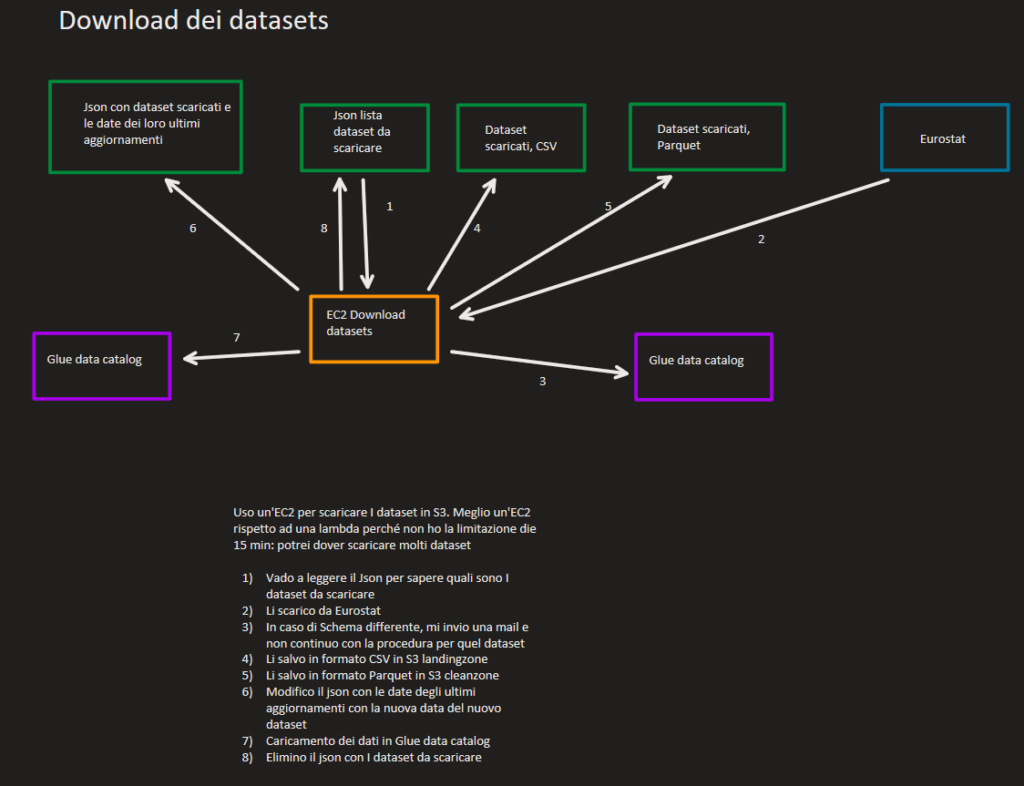
Ecco i compiti, in ordine temporale, che la nostra EC2 deve svolgere:
- Scarica i dataset da Eurostat e li salva in formato CSV nella landingzone
- Mi invia una mail in caso il dataset appena scaricato abbia uno schema differente dalla sua versione presente in S3. In caso questo accada, per quel dataset la procedura si ferma qui
- Converte i dataset in formato Parquet e li salva nella cleanzone
- Attiva i crawler necessari per catalogare questi dati in Glue Catalog
- Attiva degli ETL job per la pulizia di questi dati, che verranno infine salvati in formato parquet nella curatedzone
Come collego PowerBI ad AWS
Come anche in articoli precedenti, collego PowerBI ad AWS Athena. In questo modo posso interrogare i datasets presenti in Glue Catalog, cioè quelli risultanti dalle ETL Job attivate.
La procedura è abbastanza semplice e vi riporto il sito dove potete scaricare il programma per impostare il collegamento e i video, con una spiegazione molto semplice e chiara, che ho seguito per far funzionare il tutto.
- Scaricare il programma https://docs.aws.amazon.com/athena/latest/ug/connect-with-odbc.html
- Video https://www.youtube.com/watch?v=Tn1xZ_ZPv9w
Tutte le mie Lambda

Il confronto delle date di aggiornamento dei dataset presenti in S3 e quelli di Eurostat viene fatto da una Lambda perchè in questo modo se non c’è nulla da aggiornare, non attiviamo nemmeno la EC2 e risparmiamo un pò di soldini.
Ma in caso dovessimo scaricare e pulire nuovi dataset, non possiamo aspettarci che la EC2 si attivi da sola. Come possiamo attivarla? Beh con una Lambda ovviamente.
Codice Lambda Controllo versioni dataset
import json
import boto3
from lxml import etree
import requests
import os
def lambda_handler(event, context):
### Lettura json con lastupdate datasets e conversione in dizionario ###
s3 = boto3.client('s3')
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/database_lastupdate.json'
response = s3.get_object(Bucket=bucket_name, Key=file_key)
datasets_info_json = response['Body'].read().decode('utf-8')
datasets_metadata_S3 = json.loads(datasets_info_json)
# Creazione dizionario per annotare quali sono i dataset da scaricare da Eurostat
datasets_to_download = {}
# Creazione dizionario per annotare i metadati dei datasets
datasets_metadata_XML = {}
# Controllo ogni dataset all'interno del json in S3 con gli ultimi aggiornamenti dei datasets
for key in datasets_metadata_S3:
# Download dell'XML contenente i metadati del dataset
url = "https://ec.europa.eu/eurostat/api/dissemination/sdmx/2.1/dataflow/ESTAT/"+str(key)+"/latest"
response = requests.get(url)
if response.status_code == 200:
xml_data = response.content
else:
raise Exception(f"Errore nel download del file: {response.status_code}")
# Parsing del contenuto XML scaricato per trovare la data dell'ultimo aggioramento
root = etree.fromstring(xml_data)
namespaces = {
'm': 'http://www.sdmx.org/resources/sdmxml/schemas/v2_1/message',
's': 'http://www.sdmx.org/resources/sdmxml/schemas/v2_1/structure',
'c': 'http://www.sdmx.org/resources/sdmxml/schemas/v2_1/common'
}
Items = root.findall('.//c:Annotation', namespaces)
for i in range(0,len(Items)):
# Mi salvo le annotazioni perchè la data dell'ultimo aggiornamento è tra queste
try:
name = Items[i].find('.//c:AnnotationType', namespaces).text
except AttributeError:
print("AttributeError, check name")
try:
value = Items[i].find('.//c:AnnotationTitle', namespaces).text
except AttributeError:
print("AttributeError, check value")
datasets_metadata_XML[name] = value
# Se il dataset in Eurostat è più aggiornato del dataset in S3, allora mi annoto il nome del dataset e la data del suo ultimo aggiornamento in eurostat nei dataset da scaricare
if (int(datasets_metadata_XML['UPDATE_DATA'][0:10].replace("-", "")) > int(datasets_metadata_S3[key].replace("-", "")) ) == True:
datasets_to_download[str(key)] = datasets_metadata_XML['UPDATE_DATA'][0:10]
# Converto il dizionario con i dataset da scaricare in Json e lo carico in S3
json_data = json.dumps(datasets_to_download)
bucket_name = 'eurostatproject-landingzone'
object_name = 'datasets/datasets_to_download.json'
try:
s3.put_object(
Bucket=bucket_name,
Key=object_name,
Body=json_data
)
return {
'statusCode': 200,
'body': json.dumps('Dati caricati con successo!')
}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps(f'Errore: {str(e)}')
}
Codice Lambda per attivazione della EC2
import boto3
def lambda_handler(event, context):
ec2 = boto3.client('ec2', region_name='eu-north-1')
response = ec2.start_instances(
InstanceIds=[
'i-01059cb650e05618c'
],
)
return {
'statusCode': 200,
'body': f"Starting EC2 instance: {response['StartingInstances'][0]['InstanceId']}"
}
E come facciamo a dire alla nostra EC2 di attivare uno script specifico? Potremmo collegare l’attivazione all’avvio dell’istanza, ma una EC2 è molto versatile e potremmo voler attivare molti altri script.
Ed ecco che usiamo una nuova Lambda per andare a far eseguire uno specifico file all’interno dell’istanza.
Lambda per attivazione dello script
import boto3
import time
def lambda_handler(event, context):
ssm = boto3.client('ssm')
instance_id = 'i-01059cb650e05618c'
command = 'sudo -u ec2-user python3 /home/ec2-user/pythonScripts/createText/createText.py'
try:
response = ssm.send_command(
InstanceIds=[instance_id],
DocumentName="AWS-RunShellScript",
Parameters={'commands': [command]}
)
command_id = response['Command']['CommandId']
time.sleep(10)
command_status = ssm.get_command_invocation(
CommandId=command_id,
InstanceId=instance_id
)
return {
'statusCode': 200,
'body': f"Command status: {command_status['Status']}, Output: {command_status['StandardOutputContent']}, Errors: {command_status['StandardErrorContent']}"
}
except Exception as e:
return {
'statusCode': 500,
'body': f"Error: {str(e)}"
}
Ed infine, una volta terminata l’elaborazione dei dati e fatti partire gli ETL Job in Glue, con un’altra Lambda possiamo spegnere l’istanza, anche in questo caso per risparmiare un pò di denaro.
Lambda per spegnere l’EC2
import boto3
def lambda_handler(event, context):
ec2 = boto3.client('ec2', region_name='eu-north-1')
instance_id = 'i-01059cb650e05618c'
response = ec2.stop_instances(InstanceIds=[instance_id])
return {
'statusCode': 200,
'body': f"Stopping EC2 instance: {instance_id}"
}
Il cuore di tutto
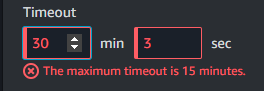
Arriviamo ora alla parte centrale di questo progetto. Il download, l’aggiornamento e la pulizia dei dati dipendono da uno script python all’interno dell’istanza EC2. Ho deciso di non usare una Lambda per queste attività perchè in caso di molti o grandi dataset potrei incorrere nel limite delle Lambda dei 15 minuti.
Di seguito l’intero codice dello script. Sotto ne vedremo i pezzi più importanti.
Script Python all’interno di EC2
import boto3
import json
# Funzione per eliminare un file da S3
def delete_file_from_s3(bucket, key):
try:
s3.delete_object(Bucket=bucket, Key=key)
except Exception as e:
print(f"Errore durante l'eliminazione del file. Funzione delete_file_from_s3. {str(e)}")
# Funzione per eliminare una cartella in S3 senza gestione della paginazione
def delete_s3_folder(bucket_name, folder_name):
try:
# Elenca tutti gli oggetti nella cartella
objects_to_delete = s3.list_objects_v2(Bucket=bucket_name, Prefix=folder_name)
if 'Contents' in objects_to_delete:
# Crea una lista di oggetti da eliminare
delete_keys = {'Objects': [{'Key': obj['Key']} for obj in objects_to_delete['Contents']]}
# Elimina tutti gli oggetti trovati
s3.delete_objects(Bucket=bucket_name, Delete=delete_keys)
print(f"Cartella {folder_name} e tutti i suoi contenuti sono stati eliminati da s3://{bucket_name}/{folder_name}")
else:
print(f"La cartella {folder_name} è vuota o non esiste.")
except Exception as e:
print(f"Errore durante l'eliminazione della cartella. Funzione delete_s3_folder. {str(e)}")
# Funzione per leggere il file JSON da S3
def read_json_from_s3(bucket, key):
try:
response = s3.get_object(Bucket=bucket, Key=key)
except Exception as e:
print(f"Errore nella lettura del file. Funzione read_json_from_s3. {str(e)}")
file_content = response['Body'].read().decode('utf-8')
json_content = json.loads(file_content)
return json_content
# Funzione per convertire un pandas dataframe in CSV e caricarlo in un S3
def save_csv_to_s3(dataframe, bucket, key):
csv_buffer = StringIO()
dataframe.to_csv(csv_buffer, index=False)
try:
s3.put_object(Bucket=bucket, Key=key, Body=csv_buffer.getvalue())
except Exception as e:
print(f"Errore nel caricamento del file. Funzione save_csv_to_s3. {str(e)}")
# Funzione per convertire un pandas dataframe in Parquet e caricarlo in un S3
def save_parquet_to_s3(dataframe, bucket, key):
parquet_buffer = BytesIO()
dataframe.to_parquet(parquet_buffer, index=False, engine='pyarrow')
# Salvataggio del file Parquet nel bucket S3 di destinazione
try:
s3.put_object(Bucket=bucket, Key=key, Body=parquet_buffer.getvalue())
except Exception as e:
print(f"Errore nel caricamento del file. Funzione save_parquet_to_s3. {str(e)}")
# Funzione per convertire un dizionario in JSON e caricarlo su S3
def upload_dict_to_s3(data_dict, bucket, key):
json_data = json.dumps(data_dict)
json_buffer = StringIO(json_data)
try:
s3.put_object(Bucket=bucket, Key=key, Body=json_buffer.getvalue())
except Exception as e:
print(f"Errore nel caricamento del file. Funzione upload_dict_to_s3. {str(e)}")
# Funzione per far partire un crawler e aspettare il suo termine
def start_and_wait_for_crawler(crawler_name):
try:
glue.start_crawler(Name=crawler_name)
except Exception as e:
print(f"Errore nell'avviare il crawler. Funzione start_and_wait_for_crawler. {str(e)}")
print(f"Crawler '{crawler_name}' avviato...")
while True:
response = glue.get_crawler(Name=crawler_name)
crawler_state = response['Crawler']['State']
if crawler_state == 'READY':
print(f"Crawler '{crawler_name}' completato.")
break
elif crawler_state == 'RUNNING':
print(f"Crawler '{crawler_name}' in esecuzione...")
elif crawler_state == 'STOPPING':
print(f"Crawler '{crawler_name}' in arresto...")
else:
print(f"Crawler '{crawler_name}' è in uno stato inaspettato: {crawler_state}")
break
time.sleep(15)
# Funzione per avviare un Glue job
def start_glue_job(job_name):
try:
response = glue.start_job_run(JobName=job_name)
job_run_id = response['JobRunId']
print(f"Glue job {job_name} avviato con successo. JobRunId: {job_run_id}")
return job_run_id
except Exception as e:
print(f"Errore durante l'avvio del Glue job {job_name}: {str(e)}")
return None
# Funzione per inviare un'email tramite SNS
def send_sns_notification(subject, message, topic_arn):
sns = boto3.client('sns', region_name='eu-north-1')
try:
sns.publish(
TopicArn=topic_arn,
Subject=subject,
Message=message
)
print("Notifica inviata con successo.")
except Exception as e:
print(f"Errore nell'invio della notifica: {str(e)}")
# Funzione per leggere un CSV da S3 e caricarlo come pandas dataframe
def load_csv_from_s3(bucket, key):
try:
response = s3.get_object(Bucket=bucket, Key=key)
csv_data = response['Body'].read().decode('utf-8')
dataframe = pd.read_csv(StringIO(csv_data))
return dataframe
except Exception as e:
print(f"Errore durante la lettura del CSV da S3: {str(e)}")
return None
######### Creo il client Glue per attivare il crawler #############
glue = boto3.client('glue', region_name='eu-north-1')
########## Lettura del Json con i dataset da scaricare ###############
s3 = boto3.client('s3')
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets_to_download.json'
datasets_to_download = read_json_from_s3(bucket_name, file_key)
#################### Per ogni dataset da scaricare: 1) scarico il dataset, 2) Rimuovo il vecchio dataset nell'S3, 3) Salvo il nuovo dataset nell'S3, 4) Modifico la data dell'ultimo aggiornamento del dataset nell'apposito CSV #######################
import pandas as pd
import pandasdmx as sdmx
from io import StringIO
from io import BytesIO
import time
datasets_not_to_update = []
######### Scarico il dataset ###########
for dataset in datasets_to_download:
estat = sdmx.Request('ESTAT')
data_msg = estat.data(dataset)
data = data_msg.to_pandas()
data_reset = data.reset_index()
print(data_reset)
######## Controllo che lo schema del dataset scaricato coincida con lo schema del dataset già in S3 ##########
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.csv'
existing_df = load_csv_from_s3(bucket_name, file_key)
if existing_df is not None:
# Confronta lo schema del CSV esistente con quello di `data_reset`
if not set(existing_df.columns) == set(data_reset.columns):
print("Schema mismatch! Fermando la procedura.")
# Invia una notifica SNS
sns_topic_arn = 'arn:aws:sns:eu-north-1:864981732574:dataset_upload_failure_schema_mismatch'
subject = f"Schema mismatch nel dataset {dataset}"
message = f"Il dataset {dataset} scaricato ha uno schema diverso rispetto a quello già presente su S3."
send_sns_notification(subject, message, sns_topic_arn)
datasets_not_to_update.append(dataset)
continue
else:
print("Nessun dataset esistente trovato, procedo con il caricamento del nuovo dataset.")
######### Elimino la versione precedente dello stesso dataset da S3 landing zone #######
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.csv'
delete_file_from_s3(bucket_name, file_key)
######### Elimino la versione precedente dello stesso dataset da S3 cleanzone #######
bucket_name = 'eurostatproject-cleanzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.parquet'
delete_file_from_s3(bucket_name, file_key)
######### Elimino la versione precedente dello stesso dataset da S3 curatedzone #######
bucket_name = 'eurostatproject-curatedzone'
folder_name = 'datasets/datasets/'+str(dataset)+'/'
delete_s3_folder(bucket_name, folder_name)
######## Salvo il nuovo dataset nell'S3 in formato CSV nella landingzone ########
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.csv'
save_csv_to_s3(data_reset, bucket_name, file_key)
######## Salvo il nuovo dataset nell'S3 in formato Parquet nella cleanzone ########
bucket_name = 'eurostatproject-cleanzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.parquet'
save_parquet_to_s3(data_reset, bucket_name, file_key)
####### Faccio partire il crawler nella cartella specifica del dataset ########
crawler_name = str(dataset)+'-crawler'
start_and_wait_for_crawler(crawler_name)
########## Faccio partire l'ETL Job in Glue per pulire i dati in cleanzone e caricarli in curatedzone ###########
start_glue_job(str(dataset))
print("Iniziato glue job "+str(dataset))
####### Carico in S3 la versione aggiornata del Json con le date dell'ultimo aggiornamento dei dataset ########
for dataset in datasets_not_to_update:
datasets_to_download.pop(dataset)
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/database_lastupdate.json'
datasets_lastUpdate = read_json_from_s3(bucket_name, file_key)
for dataset in datasets_to_download:
datasets_lastUpdate[dataset] = datasets_to_download[dataset]
delete_file_from_s3(bucket_name, file_key)
upload_dict_to_s3(datasets_lastUpdate, bucket_name, file_key)
######## Eliminazione del json con la lista dei datasets da scaricare ########
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets_to_download.json'
delete_file_from_s3(bucket_name, file_key)
La prima cosa che faccio è leggere il Json di output della prima Lambda, contenente i dataset che devo scaricare da Eurostat.
Codice
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets_to_download.json'
datasets_to_download = read_json_from_s3(bucket_name, file_key)
Inizia poi un ciclo for in cui per ogni dataset da aggiornare faccio le seguenti azioni:
1. Come prima cosa controllo che il dataset in Eurostat e il dataset in S3 abbiamo lo stesso schema. È importante fare questo controllo perchè altrimenti non potremmo essere certi della buona riuscita dell’ETL job associato a quel dataset che lanceremo poi. Se gli schemi sono differenti, fermo la procedura per quel dataset e mi mando una email contenente il suo nome. In un secondo momento dovrò a capire quali sono le differenze e adattare l’ETL Job di Glue di conseguenza ed attivarlo una volta manualmente.
2. Una volta appurato che è presente un dataset da scaricare e che è compatibile con le procedure che già abbiamo, faccio spazio per i nuovi dati. Li elimino dalla landing zone, cleanzone e curated zone:
Codice
######### Elimino la versione precedente dello stesso dataset da S3 landing zone #######
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.csv'
delete_file_from_s3(bucket_name, file_key)
######### Elimino la versione precedente dello stesso dataset da S3 cleanzone #######
bucket_name = 'eurostatproject-cleanzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.parquet'
delete_file_from_s3(bucket_name, file_key)
######### Elimino la versione precedente dello stesso dataset da S3 curatedzone #######
bucket_name = 'eurostatproject-curatedzone'
folder_name = 'datasets/datasets/'+str(dataset)+'/'
delete_s3_folder(bucket_name, folder_name)
Un possibile miglioramento qui sarebbe quello di mantenere uno storico dei dei dati, almeno dell’ultima versione del dataset. Infatti il download da Eurostat potrebbe fallire o i dati caricati essere sbagliati per una qualsiasi ragione. Potremo lamentarci con Eurostat, ma nel frattempo la nostra azienda rimarrebbe senza quel dataset.
3. Il terzo step è quello di ripopolare le tre “zone” con i nuovi dati. Inizio con la landingzone con i dati in CSV, per poi passare al parquet nella cleanzone, attivare dei Glue Crawler e infine gli ETL Jobs per la curatedzone.
Codice
######## Salvo il nuovo dataset nell'S3 in formato CSV nella landingzone ########
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.csv'
save_csv_to_s3(data_reset, bucket_name, file_key)
######## Salvo il nuovo dataset nell'S3 in formato Parquet nella cleanzone ########
bucket_name = 'eurostatproject-cleanzone'
file_key = 'datasets/datasets/'+str(dataset)+'/'+str(dataset)+'.parquet'
save_parquet_to_s3(data_reset, bucket_name, file_key)
####### Faccio partire il crawler nella cartella specifica del dataset ########
crawler_name = str(dataset)+'-crawler'
start_and_wait_for_crawler(crawler_name)
########## Faccio partire l'ETL Job in Glue per pulire i dati in cleanzone e caricarli in curatedzone ###########
start_glue_job(str(dataset))
print("Iniziato glue job "+str(dataset))
4. Quarto e ultimo step è quello di sistemare i Json che ho usato per tenermi nota di quali sono i dataset da aggiornare. In questo modo tutto è ritornato al punto di partenza, ma ora con i dataset aggiornati.
Codice
####### Carico in S3 la versione aggiornata del Json con le date dell'ultimo aggiornamento dei dataset ########
for dataset in datasets_not_to_update:
datasets_to_download.pop(dataset)
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/database_lastupdate.json'
datasets_lastUpdate = read_json_from_s3(bucket_name, file_key)
for dataset in datasets_to_download:
datasets_lastUpdate[dataset] = datasets_to_download[dataset]
delete_file_from_s3(bucket_name, file_key)
upload_dict_to_s3(datasets_lastUpdate, bucket_name, file_key)
######## Eliminazione del json con la lista dei datasets da scaricare ########
bucket_name = 'eurostatproject-landingzone'
file_key = 'datasets/datasets_to_download.json'
delete_file_from_s3(bucket_name, file_key)
Un’ultima pulizia
Come detto nel paragrafo precedente, uso degli ETL Jobs per pulire i dati prima di caricarli nella curatedzone, in Athena e di conseguenza in PowerBI.
Sono molto semplici, ma ogni dataset deve avere la sua ETL specifica. In questo modo direttamente dall’EC2 possiamo chiamare l’ETL giusta al momento giusto. Vediamone un esempio:
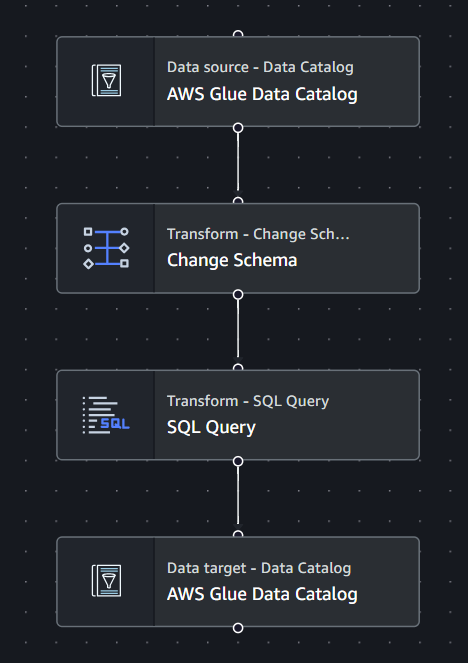
Come prima cosa, con il blocco “Change Schema”, andiamo a eliminare eventuali colonne inutili e a rinominare colonne poco chiare.
Nel caso dei dataset che ho analizzato, anche i dati all’interno sono codificati con abbreviazioni. Per rendere il report in PowerBi più immediato e facile da capire, con qualche riga di SQL modifico questi dati ( i valori sono “particolari”, ma c’è la spiegazione a fine articolo 😉).
Eliminazione delle abbreviazioni con SQL
SELECT *,
CASE
WHEN offence = 'ICCS0101' THEN 'Intentional homicide'
WHEN offence = 'ICCS0102' THEN 'Attempted intentional homicide'
WHEN offence = 'ICCS020111' THEN 'Serious assault'
WHEN offence = 'ICCS020221' THEN 'Kidnapping'
WHEN offence = 'ICCS0301' THEN 'Sexual violence'
WHEN offence = 'ICCS03011' THEN 'Rape'
WHEN offence = 'ICCS03012' THEN 'Sexual assault'
WHEN offence = 'ICCS0302' THEN 'Sexual exploitation'
WHEN offence = 'ICCS030221' THEN 'Child pornography'
WHEN offence = 'ICCS0401' THEN 'Robbery'
WHEN offence = 'ICCS0501' THEN 'Burglary'
WHEN offence = 'ICCS05012' THEN 'Burglary of private residential premises'
WHEN offence = 'ICCS0502' THEN 'Theft'
WHEN offence = 'ICCS05021' THEN 'Theft of a motorized vehicle or parts thereof'
WHEN offence = 'ICCS0601' THEN 'Unlawful acts involving controlled drugs or precursors'
WHEN offence = 'ICCS0701' THEN 'Fraud'
WHEN offence = 'ICCS0703' THEN 'Corruption'
WHEN offence = 'ICCS07031' THEN 'Bribery'
WHEN offence = 'ICCS07041' THEN 'Money laundering'
WHEN offence = 'ICCS0903' THEN 'Acts against computer systems'
WHEN offence = 'ICCS09051' THEN 'Participation in an organized criminal group'
ELSE offence
END AS offence
FROM myDataSource;
Infine, salvo il dataset nella CuratedZone e aggiorno la relativa tabella in Athena.
Automatizziamo
Sarebbe decisamente noioso mettere una persona ad attivare manualmente ogni singola Lambda, aspettare la sua esecuzione, per poi passare alla successiva. Fortuna che possiamo rendere tutto automatico con una StepFunction e attivarla una volta al mese grazie ad un segnale da EvenBridge.
Proprio in EventBridge dobbiamo creare un Cron job con queste caratteristiche:

Tradotto significa: attiva questo cron job ogni primo giorno del mese, in ogni mese, in ogni anno, indipendentemente da che giorno sia (Lunedì, Martedì…).
Associamo a questo cron la nostra StepFunction:
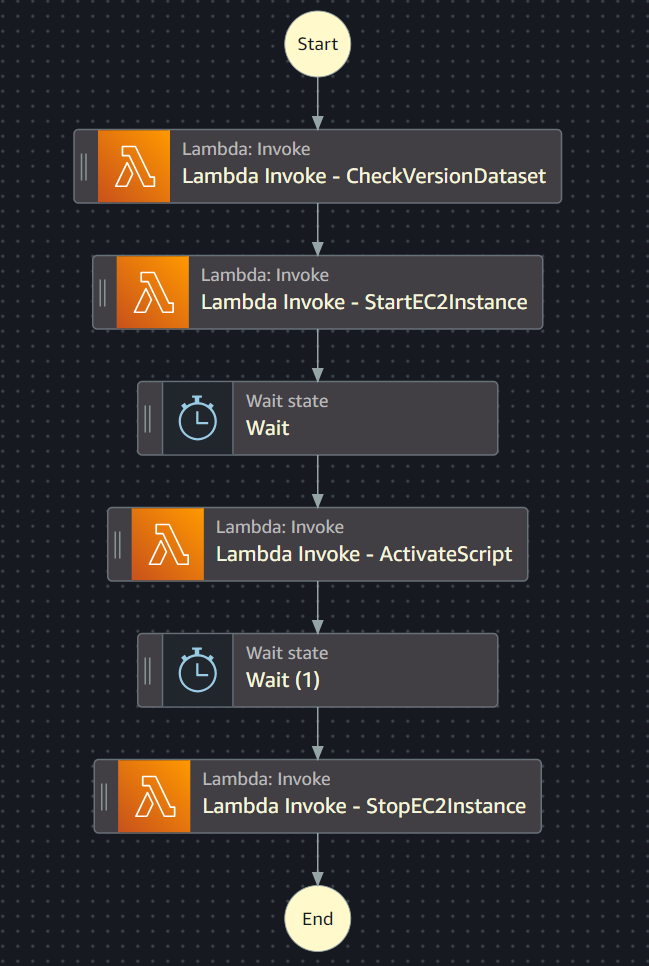
Come vedete andiamo ad attivare prima la Lambda per la creazione del Json con i dataset da scaricare, per poi passare all’attivazione dell’EC2, all’esecusione dello script python in essa e allo spegnimento della EC2.
In questo modo noi non dovremo più fare nulla ma sapremo di avere sempre i dati aggiornati, puliti e organizzati come piace a noi, con un scarto di al massimo un mese rispetto a quelli presenti in Eurostat.
Risultato finale
Qualche mese fa ho partecipato ad un TedX dove una speaker, un avvocato, raccontava della sua attività di volontariato. Aiutava i detenuti a far valere i loro diritti e a ottenere quindi una migliore condizione di vita durante la detenzione. Un punto su si era soffermata era il sovraffollamento nelle celle, un problema di certo non nuovo in Italia.
Me ne sono ricordato quando ho spulciato tutti i dataset di Eurostat alla ricerca di un qualcosa da approfondire, un qualcosa di insolito da utilizzare per quest’articolo.
Ho deciso quindi di utilizzare i dataset relativi alle situazioni all’interno delle carceri dei vari paesi europei e di creare una dashboard in PowerBI per visualizzare questi dati.
Il report è diviso in 2 pagine: nella prima possiamo trovare una overview a livello europeo, mentre nella seconda possiamo vedere nel dettaglio la situazione di uno stato specifico.
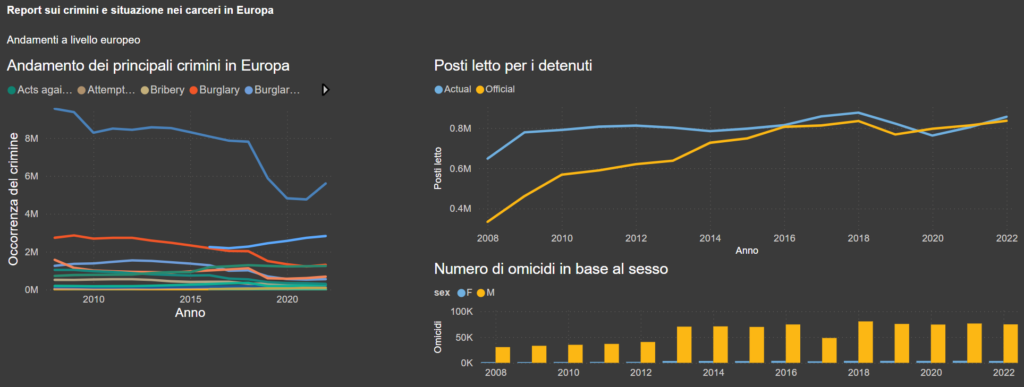
A sinistra vediamo i crimini più riportati in questi dataset, quindi le motivazioni principali per cui le persone sono detenute.
Vediamo come Furto sia il crimine più registrato. Non mi pare una cosa molto strana, visto che sotto questa definizione possono rientrare molti crimini, dal furto di auto al furto nelle case altrui.
Per quanto riguarda i posti letto per i detenuti, la capienza quindi delle carceri, la situazione è migliorata di molto negli ultimi anni. Vediamo nel grafico a destra come il fenomeno del sovraffollamento sia stato quasi completamente risolto (a livello aggregato).
Vediamo ora la situazione in Italia:
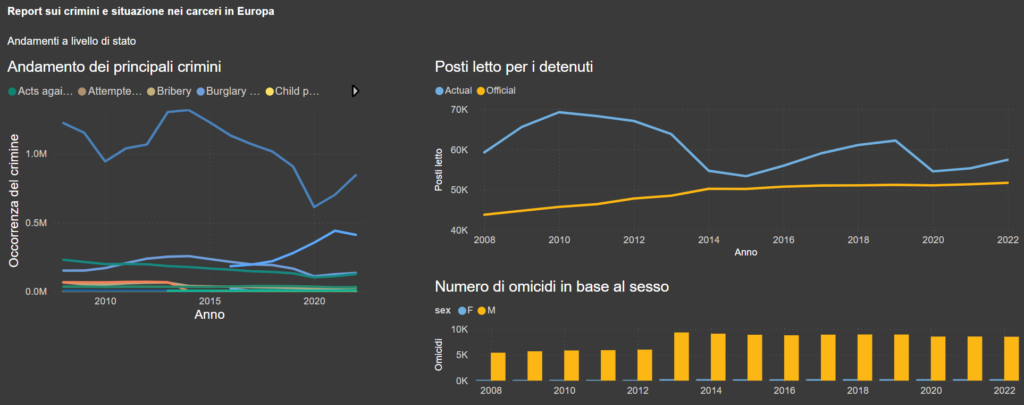
I crimini più popolari nel nostro paese sono in linea con quelli in Europa, con Furto e Frode alle prime posizioni.
Per quanto riguarda il sovraffollamento, siamo migliorati molto rispetto alla situazione nel 2010, ma non abbiamo ancora risolto il problema. Anzi, pare che negli ultimi anni ci sia stato un peggioramento.
Infine, era presente un dataset che divideva la popolazione dei detenuti per alcuni crimini in base al sesso. Senza sorpresa, ho scoperto che la grande maggioranza dei detenuti incriminati di omicidio sono uomini.
Conclusione
Grazie a questa dashboard posso capire meglio le parole della speaker. Il problema del sovraffollamento in Europa e nel nostro paese esiste veramente, non è di certo una tematica nuova e si è già fatto molto per migliorare la situazione.
Eurostat offre un servizio molto importante. Permette anche a normali cittadini di conoscere le situazioni e i cambiamenti che avvengono all’interno della comunità europea, rendendoci capaci di approfondire argomenti di nostro interesse e di smentire o appoggiare le opinioni di giornalisti, politici e altre figure che continuamente tentano di influenzare la nostra percezione dell’attualità.